AI для финансиста
Галлюцинации нейросетей в финансовых данных: чеклист проверки перед тем как подписать
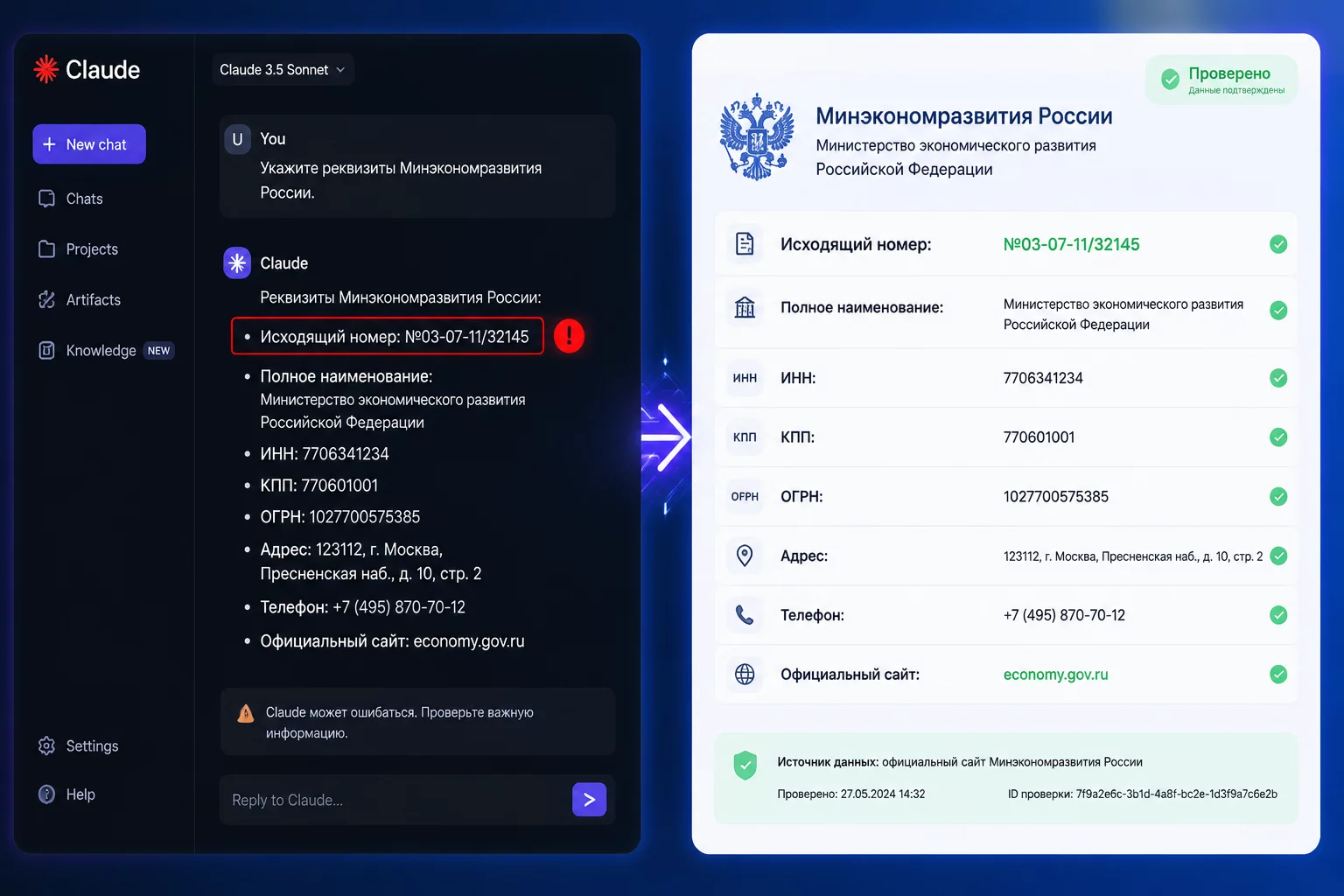
Финансовый директор отправляет ответ на требование ФНС. Нейросеть помогла составить: нашла позицию, сослалась на письмо Министерства финансов, указала номер и дату. Всё убедительно. Потом КонсультантПлюс, и такого письма нет. Этот сценарий я наблюдаю на разборах раз в несколько недель, и он давно не удивляет. По моей практике с 800+ выпускниками курса, каждый третий ответ нейросети по налоговой нормативке без системной инструкции содержит хотя бы один выдуманный факт. Разница между опытным и неопытным пользователем нейросети не в том, получает ли он галлюцинации, а в том, ловит ли их до подписи. В этой статье разбираю пять типов галлюцинаций в финансовых данных, даю 10 промптов для принудительного снижения риска, три кейса с реальными потерями в рублях и часах, и чек-лист из 12 пунктов, который защищает финансиста перед тем как поставить подпись. Актуально на 18 июня 2026 года. Я Натали Васильева, продюсер онлайн-школы «Финансовый директор | Мастер CFO».
Что такое галлюцинация нейросети: определение без технического жаргона
Прямой ответ: галлюцинация нейросети это правдоподобный, но выдуманный ответ. Языковая модель устроена так, что предсказывает наиболее вероятное следующее слово или фрагмент текста. Она не хранит проверенные факты в базе данных, не открывает КонсультантПлюс и не умеет по умолчанию останавливаться и говорить «я не знаю».
Когда вы спрашиваете «на какую статью НК опирается этот вычет», модель строит текст, который выглядит как правильный ответ: номер статьи, название, краткое описание. Большинство таких ответов верные, потому что модель обучена на огромном количестве юридических и бухгалтерских текстов. Но часть ответов выдуманы с той же уверенностью, что и верные. Модель не знает, где она знает, а где угадывает.
Это не дефект, который однажды починят разработчики. Это архитектурное свойство всех современных языковых моделей. В июне 2026 года GPT-5.5, Claude Sonnet 4.6, Gemini 2.5 и DeepSeek V3.2 все галлюцинируют. Более новые и крупные модели делают это реже, но не перестают.
Хорошая новость: поведение модели управляемо. Заставить её отмечать непроверенное, считать в коде вместо «в уме», говорить «не уверен» на спорных вопросах — реально. Но по умолчанию этого не происходит. По умолчанию модель уверенно называет несуществующее письмо Минфина с правдоподобным номером и датой.
Ключевое слово «по умолчанию». Именно с этим мы работаем.
Почему финансовые данные притягивают галлюцинации

Нормативная база меняется часто, цифры выглядят убедительно, а цена ошибки высокая: три причины, по которым финансовый контекст это зона повышенного риска галлюцинаций.
Финансовые данные это не самая сложная тема для нейросетей, но самая опасная для непойманных ошибок. Три причины.
Первая: нормативная база меняется часто. Ставки налогов, письма Минфина, судебные прецеденты обновляются регулярно. Модель обучена на исторических данных и уверенно называет ставку 2023 года как актуальную в 2026-м. Она не знает, что что-то изменилось: у неё нет доступа к живому КонсультантПлюс или сайту ФНС. Временная галлюцинация это не ошибка невнимательности, а структурное ограничение технологии.
Вторая: цифры выглядят убедительно. Если модель напишет «НДС с 1 240 000 рублей составит 206 666,67 рублей», это выглядит как точный расчёт. Но модель не считала, а предсказывала правдоподобное число. Арифметическая галлюцинация почти неотличима от верного ответа на первый взгляд, особенно если финансист устал, торопится или доверяет инструменту больше, чем стоит.
Третья: цена ошибки высокая. Неверная ссылка в блог-статье это репутационный ущерб. Неверная ссылка в ответе на требование ФНС это штраф, доначисление, возможно уголовная ответственность для главбуха. Финансовая документация это зона, где ошибка стоит не только времени, но и денег, репутации и иногда свободы.
Именно поэтому финансисту нужен специфический протокол работы с нейросетями, а не стандартный подход «попробовал, ошибся, переспросил». Переспросить у налоговой уже не получится.
Пять типов галлюцинаций, которые опасны финансисту в 2026 году
Не все галлюцинации одинаково опасны. Одна портит форматирование таблицы, другая приводит к штрафу. Я разбиваю их на пять типов по зоне риска — от дорогих к дорогим.
Тип 1. Арифметические галлюцинации. Модель считает в уме, а не выполняет код, и ошибается в цифрах. На коротком расчёте это незаметно, на таблице из 300 строк с несколькими уровнями группировки ошибки накапливаются. Финансист смотрит на правдоподобную сумму в итоговой строке и принимает её. Признаки: слишком округлённые итоги в сложных расчётах, отсутствие промежуточных шагов, несоответствие строк итоговой сумме.
Конкретный пример арифметической галлюцинации из практики: попросила GPT-5.5 без системной инструкции рассчитать НДС с суммы 1 240 000 рублей по ставке 20%. Правильный ответ: 1 240 000 / 1,2 × 0,2 = 206 666,67 рублей. Модель ответила: «НДС составит 248 000 рублей». Это 20% от базы, а не из суммы с НДС. Ошибка методологическая, а не арифметическая — но выдана с уверенностью верного ответа. Финансист, который не знал разницы между «НДС сверху» и «НДС в том числе», принял бы этот ответ. Когда попросила посчитать в коде, код написал правильно с первого раза.
Тип 2. Нормативные галлюцинации. Самые опасные для финансиста. Модель называет несуществующее письмо Министерства финансов с конкретным номером и датой, ссылается на устаревшую редакцию статьи НК, называет неверную ставку налога. Это выглядит убедительно, и именно этот тип чаще всего приводит к реальным потерям. По моей практике, нормативные галлюцинации встречаются в 30-35% ответов без системной инструкции.
Типичная нормативная галлюцинация выглядит так: «В соответствии с письмом Минфина России от 12.04.2023 №03-07-11/32145, при применении нулевой ставки НДС к экспортным операциям налогоплательщик вправе…». Номер красивый, дата правдоподобная, тема совпадает. В реальности такого письма нет. Проверка в КонсультантПлюс занимает 30 секунд. Без проверки — это уже ссылка в вашем документе.
Тип 3. Временные галлюцинации. Модель обучена на данных до определённой даты. Ставка ЦБ, ставки налогов, лимиты по спецрежимам, размер пеней меняются. Модель называет данные прошлых лет с уверенностью актуального источника. Особенно опасно: иногда совпадает, и это создаёт ложное ощущение надёжности. Потом не совпадает, и это уже проблема.
Пример: лимит остатков по УСН, лимит доходов для применения патента, максимальный размер взносов ИП — всё это меняется ежегодно. Модель, обученная на данных 2024 года, в 2026-м будет называть цифры 2024-го с той же уверенностью. По критичным параметрам финансовой отчётности всегда проверяйте актуальность на официальных сайтах ФНС и ЦБ, даже если уверены, что «ставка не менялась».
Тип 4. Контекстные галлюцинации. Модель достраивает контекст о вашей компании, которого вы не давали. Вы описали ситуацию в общих чертах, а модель добавила детали: «при вашей выручке в 500 миллионов рублей», «для производственной компании вашего масштаба». Откуда эти цифры? Из предположений на основе косвенных признаков в вашем промпте.
Я наблюдала кейс на разборе: финансист описал ситуацию в двух предложениях, не называл размер бизнеса. Модель сделала вывод «судя по масштабу дебиторки около 40 миллионов рублей, ваш бизнес относится к среднему» и далее давала рекомендации «для компании с оборотом 200-300 миллионов рублей». Откуда 200-300 миллионов? Ниоткуда. Но ученица воспроизвела эти цифры собственнику как «по анализу нейросети». Это классическая контекстная галлюцинация.
Тип 5. Источниковые галлюцинации. Модель придумывает ссылки на судебную практику, внутренние регламенты, научные статьи, которых не существует. Особенно опасно при подготовке позиции по налоговому спору: ссылка на «постановление Арбитражного суда Московского округа по делу №А40-12345/2022» выглядит весомо, а в базе ГАС Правосудие этого дела нет. Или дело есть, но по совсем другой теме.
Источниковые галлюцинации чаще встречаются в ответах, где модель пытается подкрепить нестандартную позицию. Если тема однозначная, модели хватает статьи НК. Если тема спорная, модель ищет дополнительные аргументы — и иногда придумывает их.
Если упорядочить по частоте в работе финансиста: нормативные идут первыми, временные вторыми, арифметические третьими. Контекстные и источниковые реже, но дороже по последствиям.
Как выглядит галлюцинация до того как её поймали: семь признаков
Прямой ответ: галлюцинацию часто не видно до проверки в первоисточнике. Но семь признаков позволяют насторожиться ещё на этапе чтения ответа — до того как документ ушёл в дело.
1. Точный номер и дата документа, которого вы не называли. «Письмо Минфина России от 15.03.2024 №03-07-11/23456» в ответе на общий вопрос. Модель не искала это письмо, она построила его. Всегда проверяем.
2. Округлённые итоговые числа в сложных расчётах. Задали таблицу с разными значениями, а итог вышел ровно 1 500 000 или 47,0%. Реальные расчёты почти никогда не дают круглые числа. Это признак угадывания.
3. Ставка, которую вы не проверяли. Ставка пеней за просрочку, ставка по отдельной категории плательщиков — модель назовёт что-то похожее на правду, но точность под вопросом. Всегда сверяем с сайтом ФНС.
4. Ответ без единой оговорки «не уверен» на действительно спорном вопросе. Если налоговая тема имеет несколько позиций в практике, а модель уверенно даёт одну без оговорок, это повод проверить. Реальный эксперт на спорных вопросах говорит «есть разные позиции».
5. Ссылка на суд или дело, которое невозможно найти. «По решению Арбитражного суда Московского округа по делу №А40-…» — ищете в ГАС Правосудие, не находите. Галлюцинация.
6. Данные о вашей компании, которых вы не давали. В ответе появляются цифры или характеристики, которых не было в промпте. Модель достроила контекст самостоятельно.
7. Ответ идеально совпадает с тем, что хочется услышать. Самый психологически сложный признак. Если ответ нейросети безупречно подтверждает вашу позицию, проверьте особенно тщательно: языковые модели склонны соглашаться с контекстом запроса.
Эти семь признаков не гарантируют галлюцинацию, но каждый из них это повод замедлиться и пойти в первоисточник. По моей практике, финансисты пропускают галлюцинации не потому что не умеют проверять, а потому что торопятся. Признаки — инструмент, который помогает замедлиться в нужном месте.
Ещё одно наблюдение из работы с ученицами: галлюцинации чаще всего пропускают в конце длинного ответа. Начало проверяют, середину читают по диагонали, конец уже «и так понятно». Именно в конце ответа нейросеть чаще всего подтягивает спорные ссылки на нормативку, потому что считает, что основная задача уже выполнена и детали можно додумать. Читайте ответ полностью.
Кейс 1. Главбух, выдуманное письмо Минфина и ответ в ФНС, который почти ушёл
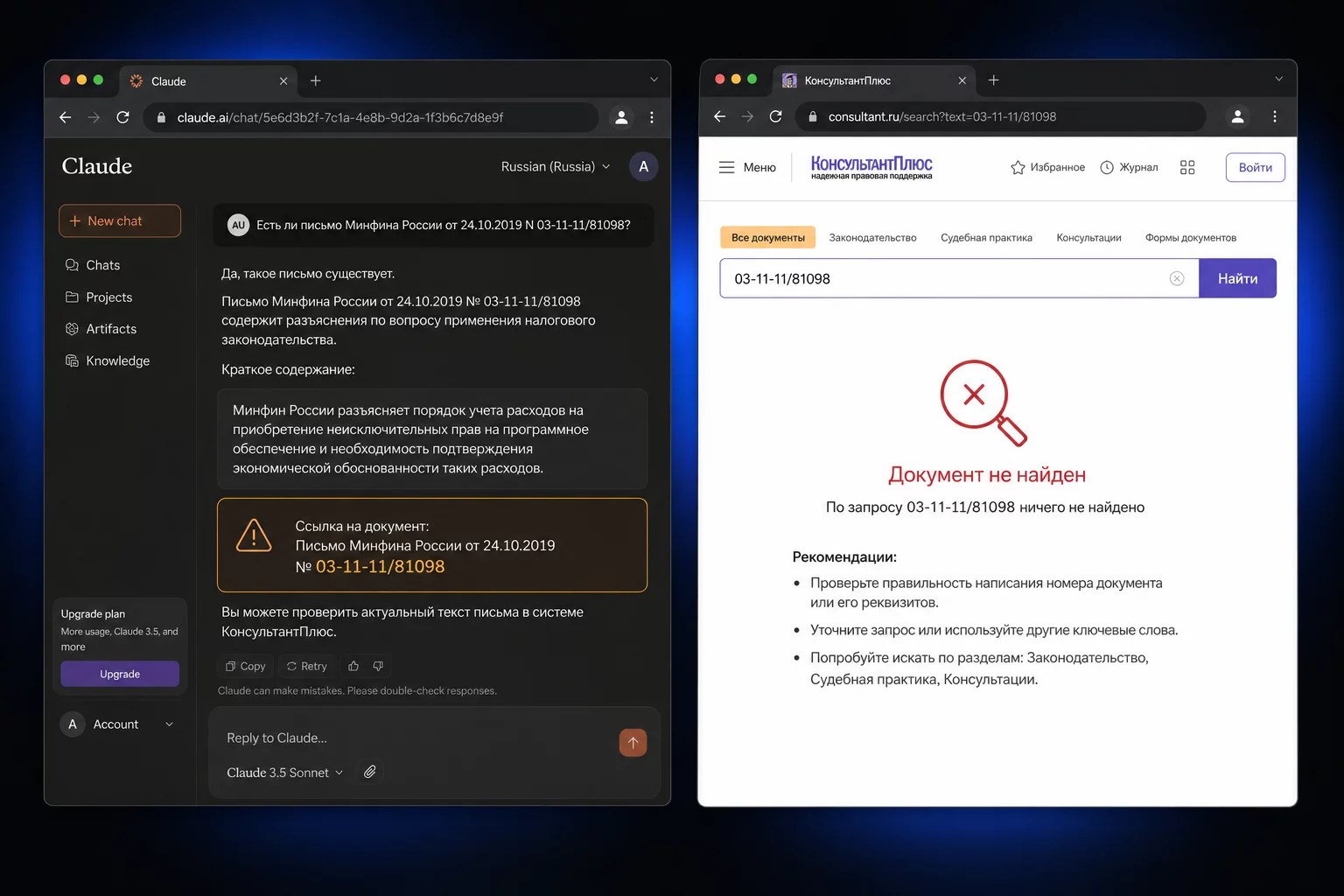
Нормативная галлюцинация: модель называет письмо Минфина с конкретным номером, которого нет ни в одной правовой базе.
Ситуация. Марина, главный бухгалтер оптовой торговой компании в Екатеринбурге, 12 лет опыта. Получила требование ФНС по вычету НДС при экспортных отгрузках. Задача нестандартная, срок три рабочих дня.
Что произошло. Обратилась к Claude с запросом: «Помоги составить ответ на требование ФНС по вычету НДС при экспорте, нужно обосновать позицию». Модель дала развёрнутый ответ: расписала позицию по двум подходам и в конце привела письмо Минфина с номером и датой, которое «подтверждает правомерность применения нулевой ставки». Красиво, убедительно, детальный номер документа.
Что остановило. За три часа до отправки коллега случайно искала это письмо для другой задачи, не нашла ни в КонсультантПлюс, ни в Гаранте, ни на сайте Минфина. Позвонила Марине. Отправку остановили.
Что обнаружила проверка. Два других письма в том же ответе — реальные. Только одно из трёх было выдуманным. Именно то, которое звучало наиболее убедительно и подкрепляло ключевой аргумент.
Что изменили. Марина переписала ответ без выдуманной ссылки. Настроила правило: все нормативные ссылки помечаются тегом [ПРОВЕРИТЬ] в промпте, проверяются в первоисточнике перед отправкой. Системная инструкция в Claude настроена один раз и работает во всех чатах проекта. С тех пор 28 недель без непойманной галлюцинации в нормативке.
Цена риска. Ссылка на несуществующий документ в ответе ФНС это не просто неловкость. Это основание для повторного требования, дополнительных вопросов, а при неблагоприятном стечении обстоятельств и доначисления. Три часа до отправки, случайная проверка коллеги — и компания не попала в ситуацию, выход из которой занял бы месяцы.
Чем галлюцинируют GPT-5.5, Claude Sonnet 4.6, Gemini 2.5 и DeepSeek V3.2
Прямой ответ: у каждой модели свой профиль ошибок. Универсально «самой честной» нет. Выбор строится на понимании, где какая ошибается чаще применительно к вашей задаче.
| Тип галлюцинации | GPT-5.5 | Claude Sonnet 4.6 | Gemini 2.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| Арифметические | Средний риск | Низкий | Низкий | Низкий, показывает ход |
| Нормативные (РФ) | Высокий | Средний | Средний | Средний |
| Временные (устаревшие данные) | Средний | Средний | Средний | Средний |
| Контекстные | Средний | Низкий | Средний | Средний |
| Источниковые | Средний | Низкий | Средний | Средний |
| Говорит «не уверен» | Иногда | Часто | Редко | Часто |
| Показывает ход рассуждения | По запросу | По запросу | По запросу | По умолчанию |
| Русская правовая база | Хорошо | Хорошо | Средне | Хорошо |
Актуально на 18 июня 2026 года.
GPT-5.5 через chatgpt.com универсален и силён в агентских сценариях. По нормативке РФ проверяем всегда: модель бывает излишне уверена там, где нужно оговориться.
Claude Sonnet 4.6 реже других выдаёт нормативные галлюцинации, чаще говорит «нужно проверить». Для задач, где цена ошибки высокая и есть длинный текст для анализа, я выбираю его. Хорошо себя ведёт в диалоге с уточнениями.
Gemini 2.5 силён в таблицах и расчётах, арифметические галлюцинации редки. С российской юридической базой стоит быть внимательнее: он реже оговаривает неопределённость на спорных нормативных вопросах.
DeepSeek V3.2 показывает ход рассуждения по умолчанию. Это технически упрощает поиск ошибки: видите, где модель свернула не туда. Для расчётов и задач с проверяемой логикой особенно удобно. Доступ из России проще, чем к остальным трём.
Главный вывод: выбор модели это второй вопрос. Первый — настройка системной инструкции и промпт с защитой. Без этого даже самая аккуратная модель выдаст галлюцинацию на сложном нормативном вопросе.
Отдельно про доступ из России. Сайты ChatGPT, Claude и Gemini из РФ напрямую не открываются, нужны специальные средства доступа, и каким способом подключаться — каждый решает сам с учётом задач и требований безопасности. Оплату зарубежных подписок принимают иностранные карты. DeepSeek и российские модели (YandexGPT, GigaChat) в этом смысле проще: к ним доступ из РФ свободнее. Для метода двух моделей разумная комбинация — Claude или GPT-5.5 в паре с DeepSeek V3.2: последний доступен без ограничений и показывает ход рассуждений по умолчанию.
Десять промптов для принудительного снижения галлюцинаций

Правильно выстроенный промпт не устраняет галлюцинации полностью, но заставляет модель отмечать непроверенное и считать в коде вместо угадывания.
Все промпты работают в GPT-5.5, Claude Sonnet 4.6 и Gemini 2.5. Копируете, подставляете свои данные (обезличенные по справочнику-мэппингу).
Промпт 1. Требование цитировать источник для каждого факта.
Промпт: требование источников (для любого нормативного вопроса)
Ты [роль, например: налоговый консультант] с 10+ лет практики.
ОБЯЗАТЕЛЬНОЕ ПРАВИЛО: для каждого факта, цифры, ставки, срока
и ссылки на нормативный акт указывай источник в квадратных
скобках [название документа + год + статья/пункт].
Если не уверен в источнике на 90%, пиши: [источник требует
проверки]. Не выдумывай реквизиты писем и дат.
Задача: [ваш вопрос].
Формат: позиция + обоснование с источниками + список что
проверить в первоисточнике.Промпт 2. Расчёт в Python, а не в уме.
Промпт: расчёт только через код
Ты финансовый аналитик с 10+ лет опыта.
ВАЖНО: не считай в уме. Для всех числовых расчётов пиши
и выполняй код на Python. Показывай ход вычислений построчно.
Если в данных есть пропуски или нечисловые значения, укажи
это отдельно, не подставляй выдуманные числа.
Данные: [прикладываете таблицу или цифры].
Задача: рассчитай [что именно].
Формат: блок кода Python + результат + вывод в 2 предложения.Промпт 3. Разбор договора с обязательными тегами верификации.
Промпт: аудит договора с защитой от галлюцинаций
Ты юрист по коммерческим договорам и финансовый контролёр
с 10+ лет практики.
Задача: найди в обезличенном договоре финансово рискованные
пункты для арендатора.
ПРАВИЛА:
- используй только текст договора, не додумывай
- если пункт отсутствует, пиши «в договоре не указано»
- все ссылки на законы помечай [ПРОВЕРИТЬ В КОНСУЛЬТАНТПЛЮС]
- если формулировка двусмысленна, прямо отметь это
Прикладываю обезличенный текст договора.
Формат: таблица (пункт, цитата, риск, рекомендация).
Под таблицей вывод 3 предложения: подписывать / торговаться / нет.Промпт 4. Налоговый вопрос с тегами обязательной проверки.
Промпт: налоговый вопрос с тегами верификации
Ты налоговый консультант с 10+ лет практики в [отрасль].
Вопрос: [ваш вопрос].
ОБЯЗАТЕЛЬНО:
1. Все ссылки на статьи НК, письма Минфина и ФНС, решения
судов помечай тегом [ПРОВЕРИТЬ В ПЕРВОИСТОЧНИКЕ].
2. Если по теме есть несколько позиций в практике, перечисли
обе, не скрывай спорное.
3. Если не уверен, прямо пиши «требует уточнения».
4. Не называй номера писем, если не можешь подтвердить.
Формат: позиция + обоснование с тегами + список что проверить.Промпт 5. Самопроверка: заставить модель найти собственные ошибки.
Промпт «Критик» (применяется после получения ответа)
Вот твой предыдущий ответ [вставьте].
Теперь сыграй роль строгого финансового аудитора и проверь
его по четырём критериям:
1. Цифры, которые посчитаны не через код — требуют проверки.
2. Ссылки на нормативные документы, в которых ты не был уверен.
3. Факты о ситуации, которых не было в исходных данных задачи.
4. Утверждения, по которым на практике может быть несколько позиций.
Будь честен. Если ответ чистый, так и скажи. Если есть
сомнения, перечисли что именно нужно проверить в первоисточнике.Промпт 6. Анализ управленческой отчётности с принудительным кодом.
Промпт: анализ P&L через Python
Ты финансовый директор с 10+ лет опыта в управленческом учёте.
Контекст: [тип бизнеса, отрасль, период].
Прикладываю обезличенный P&L за [период], колонки: статья, факт, план.
Задача: проанализируй отклонения, найди проблемные зоны.
ОБЯЗАТЕЛЬНО: считай все отклонения в коде на Python, не в уме.
Используй только данные из таблицы, не додумывай.
Если статья пустая, отметь это.
Формат: код Python + таблица (статья, факт, план, отклонение ₽,
отклонение %) + топ-3 проблемы + вывод в 3 предложения.Промпт 7. Поиск аномалий в выгрузке с защитой от арифметических галлюцинаций.
Промпт: поиск аномалий в выгрузке
Ты финансовый аналитик-аудитор с 10+ лет практики.
Прикладываю обезличенную выгрузку из 1С: [N] строк.
Колонки: дата, контрагент_маска, сумма_₽, статья_расходов.
Задача: найди аномалии.
ПРАВИЛА:
- все расчёты только через Python-код
- не суммируй вручную и не угадывай итоги
- если данных не хватает, укажи это, не додумывай
Ищи: задвоенные платежи, резкий рост контрагентов,
округлённые до 100 тыс. суммы, просрочки 30+ дней.
Формат: код + 4 таблицы по типам аномалий + вывод по каждой.Промпт 8. Ответ на требование контролирующего органа.
Промпт: черновик ответа на требование (не финальный документ)
Ты налоговый консультант с 10+ лет практики.
Задача: составь черновик ответа на требование по теме:
[тема]. Прикладываю обезличенный текст требования.
ОБЯЗАТЕЛЬНО:
- все ссылки на нормативные акты помечай [ПРОВЕРИТЬ]
- не называй номера писем Минфина без уверенности
- вместо конкретных реквизитов пиши [указать при проверке]
- если позиции по теме расходятся, обозначь альтернативы
Цель: черновик для самостоятельной проверки в первоисточниках,
а не готовый финальный документ.
Формат: позиция + обоснование + список документов + список норм
с тегами [ПРОВЕРИТЬ].Промпт 9. Сценарный расчёт с верификацией ставок.
Промпт: сценарный анализ с проверкой ставок
Ты финансовый директор с 10+ лет опыта в финансовом планировании.
Контекст: [тип бизнеса]. Прикладываю базовую финмодель.
Задача: посчитай 3 сценария: базовый, пессимистичный
(выручка -25%, расходы +10%), оптимистичный (выручка +20%).
ОБЯЗАТЕЛЬНО:
- считай в коде на Python, не в уме
- ставки налогов, которые используешь, помечай [ПРОВЕРИТЬ НА САЙТЕ ФНС]
- если данных для сценария не хватает, укажи, каких именно
Формат: код + таблица по сценариям (выручка, расходы, EBITDA,
прибыль) + вывод: при каком сценарии бизнес уходит в минус.Промпт 10. Перекрёстная проверка спорного нормативного вопроса.
Промпт: второе мнение по нормативному вопросу
Ты налоговый консультант с 10+ лет практики. Тебе дан ответ
другого консультанта по вопросу: [вопрос].
Ответ другого консультанта: [вставьте предыдущий ответ модели].
Задача: оцени этот ответ критически.
1. Где позиция правомерна и подкреплена нормами?
2. Где есть спорные места или альтернативные позиции?
3. Какие утверждения требуют обязательной проверки
в первоисточнике?
Не соглашайся автоматически. Ищи слабые места.
Формат: оценка по пунктам + список что проверить в КонсультантПлюс.Как заставить нейросеть считать в коде, а не угадывать
Это один из двух самых важных приёмов в работе с нейросетями для финансиста. Арифметическая галлюцинация почти исчезает, если заставить модель запустить настоящий код, а не строить текст, похожий на ответ.
Почему это работает. Языковая модель предсказывает вероятный текст, в том числе числа. Когда вы просите «посчитай НДС с 1 240 000», она генерирует правдоподобное число. Но когда вы добавляете «считай в коде Python», модель буквально пишет код, передаёт его интерпретатору, получает результат и вставляет в ответ. Это уже не предсказание, а вычисление.
В chatgpt.com и Claude это работает в режиме Code Interpreter или просто с запросом «пиши и выполняй код Python». В Gemini аналогичный режим. В DeepSeek V3.2 ход рассуждений с кодом показывается по умолчанию, что дополнительно облегчает проверку.
Фразы, которые включают этот режим в промпте:
Приёмы для принудительного расчёта в коде
Вариант 1 (жёсткий):
«Не считай в уме. Для всех числовых расчётов пиши код
на Python и выполняй его. Показывай ход вычислений.»
Вариант 2 (мягкий, для простых задач):
«Все итоговые цифры подтверди кодом на Python.»
Вариант 3 (для больших таблиц):
«Считай только через код. Если в данных есть пропуски,
укажи это отдельно, не подставляй выдуманные числа.»Один нюанс: просьба «считай в коде» не защищает от нормативных галлюцинаций. Модель правильно посчитает НДС по ставке 20%, но откуда взялась эта ставка, остаётся вашей проверкой. Код устраняет арифметические ошибки, системная инструкция снижает нормативные. Оба приёма нужны вместе.
Практическая рекомендация для работы с 1С: всегда прикладывайте структуру данных явно. «Выгрузка 4 200 строк, колонки: дата, контрагент_маска, сумма_₽, статья». Без описания структуры модель тратит контекст на угадывание, что в колонках, и это увеличивает риск неверной интерпретации данных.
Как проверить, что код реально выполнялся, а не был просто написан. Попросите модель показать промежуточные результаты для нескольких строк. Если код написан, но промежуточные значения совпадают с тем, что модель могла угадать «в уме», — есть подозрение, что интерпретатор не запускался, а ответ написан по шаблону. Попросите явно: «покажи значение переменной X после шага Y». Настоящий выполненный код даст точное значение, а не округлённое.
Ещё один практический приём: попросите специально допустить ошибку в данных и посмотреть, как код на неё реагирует. «Добавь в данные строку с пустым значением суммы и покажи, как код её обрабатывает». Если код реально работает, вы увидите исключение или явную обработку. Если нет — ответ будет расплывчатым.
Для больших расчётов (более 1 000 строк) всегда проверяйте итог в Excel независимо от модели. Это не недоверие к инструменту, это профессиональный стандарт: расчёт в двух системах, расхождения на выходе требуют объяснения. На дистанции это экономит время, потому что ошибку в итоге лучше найти самому, чем получить её обратно от собственника.
Хочешь посмотреть, как я прогоняю выгрузку через промпт с кодом Python в реальном времени и за 20 минут получаю таблицу аномалий? Это в эфире «AI-практикум финдира», разбираю на экране с живыми данными. Регистрация открыта.
Кейс 2. Финдир, ошибка в ставке НДС на три квартала и 240 тысяч рублей
Ситуация. Антон, финансовый директор производственной компании, 8 лет в роли, оборот около 180 миллионов рублей в год. Ежеквартально готовил управленческий анализ для собственника, включая расчёт НДС по разным видам операций.
Что произошло. Антон использовал GPT-5.5 для расчёта суммы НДС по экспортным операциям. Задал вопрос без системной инструкции, одной строкой. Модель рассчитала НДС по стандартной ставке, не применив нулевую ставку для экспорта. Расчёт был сделан в тексте, а не в коде — проверить логику по шагам было трудно. Итог выглядел правдоподобно, Антон не насторожился.
Масштаб проблемы. Три квартала подряд управленческие отчёты содержали завышенную сумму НДС, из-за чего EBITDA в отчётах выглядела ниже реальной. Собственник принимал решения о дивидендах на основе заниженных показателей. Когда в конце года аудиторы разбирали методологию, оказалось, что три квартала рентабельность отражалась хуже реальной на совокупные 240 тысяч рублей.
Как обнаружили. Аудитор попросил Антона показать расчёт НДС по экспортным операциям. Антон открыл переписку с GPT-5.5 и увидел, что код модель не писала, ставку не обосновывала, просто выдала число. Стало очевидно: откуда взялась стандартная ставка на операции с нулевой, модель не объясняла, а Антон не спрашивал.
Что изменил. Ввёл правило: все ставки налогов по экспорту в промпте помечаются [ПРОВЕРИТЬ НА САЙТЕ ФНС], а расчёт запускается только через Python-код с явным шагом «откуда ставка». Держит открытую вкладку с актуальными ставками ФНС при каждом расчёте.
Чему учит кейс. Это сложился тройной сбой: временная галлюцинация (модель применила стандартную ставку без проверки специфики операции), отсутствие кода (проверить шаги было невозможно) и отсутствие системной инструкции (модель не предупредила, что ставку нужно уточнить). Каждый из трёх по отдельности мог бы пройти незамеченным. Вместе они дали три квартала искажённой управленческой отчётности.
Системная инструкция против галлюцинаций: настраивается один раз
Системная инструкция это текст, который вы вписываете в настройки нейросети один раз и который применяется ко всем последующим чатам в этом проекте. Это самый экономичный способ снизить галлюцинации: работает в фоне, без усилий при каждом запросе.
Где настраивать:
- ChatGPT: Settings — Personalization — Custom Instructions — поле «How would you like ChatGPT to respond?»
- Claude: открыть Project — кнопка Custom Instructions
- Gemini: в меню системных инструкций в настройках
Вот инструкция, которую я рекомендую ученицам курса:
Системная инструкция против галлюцинаций (вставить один раз)
Ты финансовый и юридический эксперт для российского бизнеса.
ОБЯЗАТЕЛЬНЫЕ ПРАВИЛА:
1. Если не уверен в факте на 90%, прямо пиши: «не уверен» или
«рекомендую проверить в первоисточнике». Не выдавай
непроверенное за утверждение.
2. Все ссылки на законы (НК РФ, ГК РФ, КоАП и др.), письма
Минфина, ФНС и ЦБ, постановления судов помечай тегом
[ПРОВЕРИТЬ В КОНСУЛЬТАНТПЛЮС]. Не называй номера писем
и дат, если не можешь подтвердить.
3. Не выдумывай реквизиты документов. Если документ не можешь
идентифицировать точно, опиши суть нормы без реквизитов.
4. Для любых числовых расчётов используй код на Python.
Не считай в уме на больших данных.
5. Если для задачи не хватает данных, прямо напиши об этом.
Не достраивай контекст о компании, который я не давал.
6. Если по вопросу есть несколько позиций в практике, назови
обе или все. Не скрывай спорное.
7. Русский язык, деловой стиль, суммы в рублях.По моей практике, после установки такой инструкции частота нормативных галлюцинаций по налоговой тематике падает примерно в три раза. С 30-35% ответов с хотя бы одним выдуманным фактом до 10-12%. Это не ноль, но принципиально иной уровень работы.
Важный момент: системная инструкция работает в рамках одного проекта или чата. Если вы начинаете новый чат за пределами проекта, инструкция не применяется. Поэтому все финансовые задачи я рекомендую вести в рамках одного именованного проекта, а не в разрозненных чатах. В Claude это Projects, в ChatGPT это также Projects. Внутри проекта инструкция работает автоматически.
Ещё одна деталь, которую часто упускают: системная инструкция это не молитва, а рабочий инструмент. Её нужно дорабатывать под свои задачи. Финансист в сфере ритейла добавит к стандартной инструкции «особое внимание на НДС при дистанционной торговле». Бухгалтер с M&A-аналитикой добавит запрет на ссылки на сделки без указания открытого источника. Один раз настроенная инструкция под специфику вашей отрасли работает как личная защита, а не как стандартная «для всех».
Оставшееся ловит финальный фильтр: чек-лист из 12 пунктов перед подписью и ваша профессиональная проверка. Системная инструкция это первый рубеж, а не последний.
Метод двух моделей: когда расхождение это предупреждение
Прямой ответ: задайте один и тот же вопрос двум разным моделям. Расхождение в ответах по цифрам или нормативным ссылкам это сигнал: идём в первоисточник, не принимаем ни один вариант без проверки.
Почему это работает. Разные модели обучены на разных наборах данных и архитектурно генерируют ответы по-разному. Вероятность того, что обе выдумают одно и то же письмо Минфина с одним и тем же номером, мала. Если расходятся — один из вариантов выдуман, а возможно оба. Если совпадают по сути — вероятность галлюцинации ниже, хотя и не равна нулю.
Практика применения:
Когда применять. Спорный нормативный вопрос с неочевидным ответом. Ставки или лимиты, которые могли измениться. Ссылки на судебную практику. Ситуации, где ответ будет использоваться в официальном документе.
Как применять. Задаёте один и тот же вопрос с одинаковым промптом в двух разных чатах, GPT-5.5 и Claude Sonnet 4.6. Сравниваете ответы по ключевым позициям: цифры, ссылки на документы, суть рекомендации. Расхождение по любому из этих пунктов это стоп-сигнал.
Чего метод не даёт. Совпадение ответов не гарантирует правильность. Обе модели обучены на похожих корпусах и могут систематически ошибаться в одном и том же. Метод снижает риск случайной галлюцинации, но не устраняет системную. Для нормативных ссылок КонсультантПлюс всё равно обязателен.
Бонус метода: он заставляет вас прочитать два ответа, а не один. Это само по себе снижает риск пропустить ошибку.
Практические нюансы применения метода. Первый: задавайте вопрос в точно одинаковой формулировке. Если промпт для одной модели отличается от промпта для другой, расхождение может быть из-за разного вопроса, а не из-за галлюцинации. Второй: не сравнивайте ответы по длине или стилю — только по фактическим утверждениям: цифры, ссылки, ставки, даты. Третий: если ответы совпадают, но оба кажутся слишком уверенными для спорной темы, всё равно идём в первоисточник. Совпадение двух галлюцинаций не превращает их в факт.
Когда метод применять нецелесообразно: простые вопросы без нормативной составляющей (структурировать текст, переписать абзац, составить список), задачи, где главное скорость, а не точность, и ситуации, когда оба источника недоступны (один из инструментов лежит технически). В остальных случаях для нормативных вопросов метод двух моделей это обязательный элемент рабочего протокола, а не опция.
Кейс 3. Перекрёстная проверка при M&A-аналитике спасла переговоры
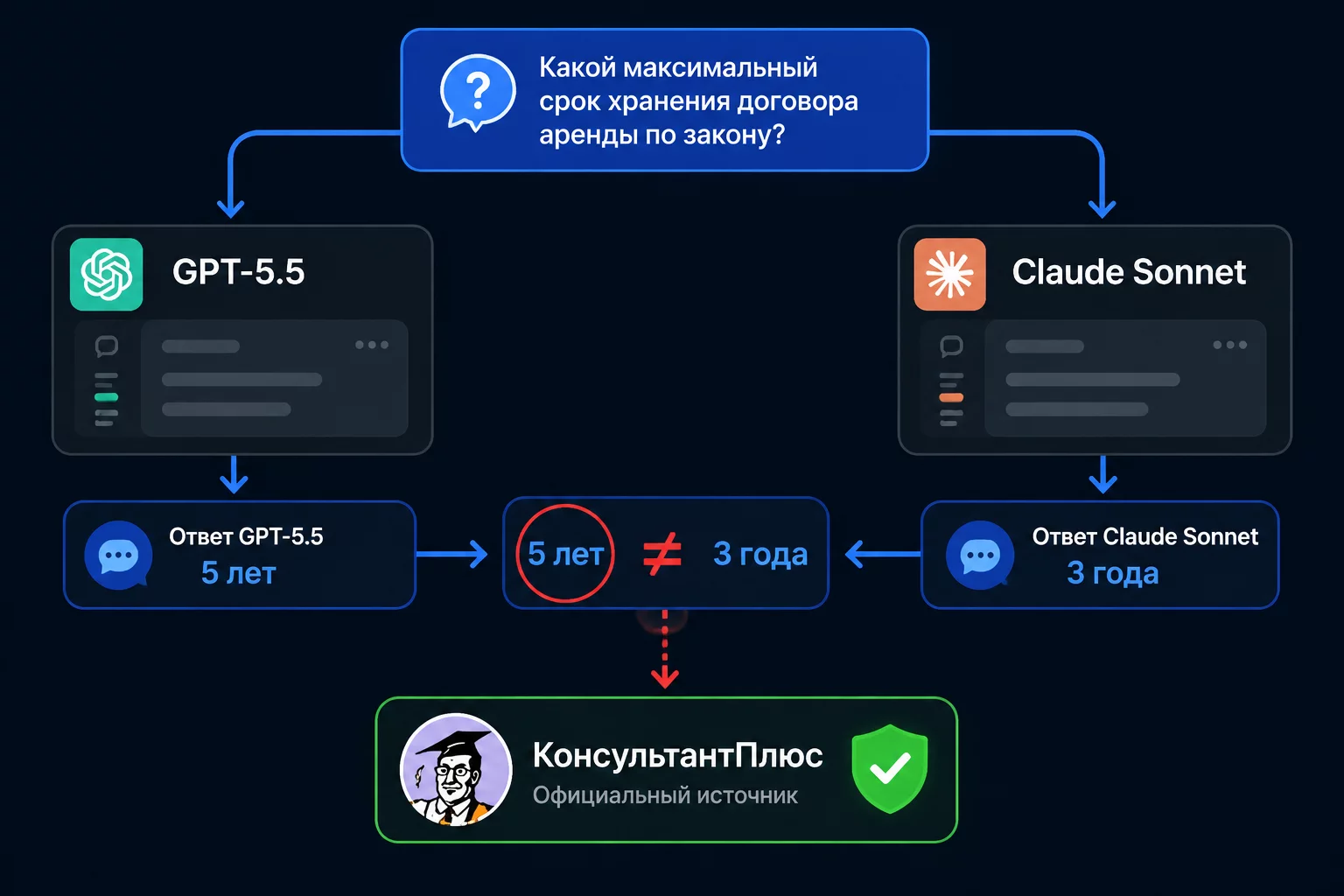
Метод двух моделей: одинаковый вопрос задаётся GPT-5.5 и Claude. Расхождение в цифрах или ссылках — сигнал идти в первоисточник.
Ситуация. Ирина, финансовый менеджер инвестиционного подразделения, работает с M&A-аналитикой, 6 лет опыта. Готовила оценку для переговоров о приобретении бизнеса в смежной отрасли. Сроки сжатые, аналитики нет, нейросеть как ускоритель.
Что сделала. Использовала GPT-5.5 для расчёта мультипликаторов и оценки по сопоставимым сделкам. Получила таблицу с цифрами и ссылками на сделки в отрасли за последние три года. Всё выглядело профессионально. Перед тем как нести собственнику, по привычке прогнала те же вопросы через Claude Sonnet 4.6.
Что обнаружила. Два из пяти приведённых «сопоставимых» M&A-сделок у GPT-5.5 не подтвердились в Claude. Один мультипликатор отличался на 1,8x при ключевом расчёте стоимости. Один показатель EBITDA в «сопоставимой сделке» был описан с расхождением: в одной модели цифра одна, в другой другая на ту же компанию.
Что сделала дальше. По каждому расхождению прошла в открытые источники: профессиональные агрегаторы M&A-данных, пресс-релизы участников сделок. Из пяти «сделок» две оказались выдуманными GPT-5.5, одна реальной, но с неверным EBITDA. Итоговая оценка ушла собственнику с тремя реальными сопоставимыми сделками вместо пяти сомнительных.
Что дало в переговорах. На встрече с продавцом те же три сопоставимые сделки оппонент знал и не оспаривал. Если бы в материале были выдуманные сделки, это могло бы выйти на переговорах и сломать доверие на ключевом этапе.
Цена 30 минут перекрёстной проверки. 30 минут дополнительного времени и одна подписка на Claude против риска выйти на M&A-переговоры с выдуманными данными.
Чек-лист «Перед подписью»: 12 пунктов верификации результата нейросети
Промпт-каркас и системная инструкция работают на входе. Этот чек-лист — на выходе. 12 вопросов, которые задаём перед тем как подписать результат или отправить его дальше.
1. Расчёты. Все числа в ответе получены через код на Python, а не угаданы моделью? Если нет — запустить расчёт заново через код.
2. Статьи НК. Все упомянутые статьи Налогового кодекса открыты в КонсультантПлюс или Гаранте? Статья существует, актуальна и говорит именно о том, о чём написано?
3. Письма Минфина и ФНС. Каждое письмо с номером и датой найдено в базе? Если не найдено, ссылку удаляем.
4. Актуальность ставок. Ключевая ставка ЦБ, ставки налогов, лимиты по спецрежимам, размеры пеней проверены на сайте ФНС или ЦБ на текущую дату?
5. Арифметика. Нет ли подозрительно округлённых итогов в сложных расчётах? Нет ли несоответствия между строками и итоговой суммой?
6. Метод двух моделей. Спорный нормативный вопрос проверен в двух моделях? Есть ли расхождения? Если есть — первоисточник обязателен.
7. Прочитан весь ответ. Не скопированы ли блоки не читая? Прочитан ли ответ целиком, как текст сотрудника на проверке?
8. Нет ли додуманного контекста. Все выводы опираются только на данные из задачи, а не на домыслы модели о вашей компании?
9. Нет ли данных, которых не давали. Если модель называет цифры или характеристики, которых не было в промпте, — запросить источник. Если источника нет, удалить.
10. Судебная практика. Любая ссылка на суд или дело проверена через ГАС Правосудие или КонсультантПлюс?
11. Терминология и реквизиты. Нет ли устаревших названий органов, упразднённых форм, старых номеров счетов? Актуальны ли упомянутые реквизиты?
12. Ответственность. Готовы ли вы лично отвечать за этот документ, если в нём найдётся ошибка? Если ответ «не уверен», документ идёт на дополнительную проверку.
Двенадцать галочек — и материал можно отправлять. Пропустить один пункт это не лень, а риск. По моей практике, большинство инцидентов с галлюцинациями в реальных документах ловится именно на пунктах 2, 3 или 4.
Где граница: что нейросеть будет галлюцинировать всегда
Это важный раздел, чтобы не переоценивать возможности инструментов. Даже с системной инструкцией, расчётом в коде и методом двух моделей есть зоны, где вероятность ошибки остаётся высокой.
Свежие изменения законодательства. Всё, что вышло за последние несколько месяцев до даты обучения модели, ей неизвестно. Новые письма Минфина, изменённые лимиты, новые формы отчётности. Никакая системная инструкция это не исправит: модель честно не знает, что изменилось.
Региональная специфика. Местные нормативные акты, специфика конкретной ИФНС, региональные ставки по некоторым налогам. Модель знает общее, региональное — хуже.
Судебная практика последних лет. Новые прецеденты, которых нет в открытых базах на дату обучения, модель выдумает или проигнорирует. Для налоговых споров это критично.
Внутренняя специфика вашей компании. Договорённости, которые не задокументированы, история переговоров с конкретным контрагентом, неформальные условия. Модель не знает того, чего не написали в промпте, и она будет достраивать это самостоятельно, если не остановить явным запретом.
Межотраслевые нюансы. Там, где два блока права пересекаются (трудовое и налоговое, таможенное и НДС при экспорте), модели чаще ошибаются. Они хорошо знают каждую область по отдельности, но на пересечении хуже.
Общий принцип: чем более специфична задача, тем выше риск галлюцинации. Это не повод отказаться от нейросетей. Это повод понять, где расположен рубеж вашей собственной проверки — и никогда не пускать за него документы без неё.
Ещё один блок постоянных галлюцинаций: математика на границах. Ставка НДС при смешанных операциях, налог на прибыль при наличии льготируемой деятельности, страховые взносы у ИП с переменным доходом — всё, где применяется несколько правил одновременно. Модель знает каждое правило по отдельности, но на пересечении начинает угадывать, какое применять первым. Расчёт в коде снижает риск, но системная проверка нормы обязательна.
Что делать с этим знанием на практике. Разбейте свои задачи на три категории. Первая: всё, где риск галлюцинации низкий (черновики писем, структурирование данных, перефразирование) — работаете без особых проверок. Вторая: задачи со средним риском (анализ договора, управленческая отчётность без нормативки) — промпт с тегами [ПРОВЕРИТЬ] и расчёт в коде. Третья: высокий риск (налоги, нормативные ссылки, судебная практика) — все 12 пунктов чек-листа плюс первоисточник обязателен. Три категории, три разных протокола. Не нужно проверять всё с одинаковой интенсивностью: это замедляет работу без пропорционального снижения риска.
Как организовать защиту от галлюцинаций в команде бухгалтерии
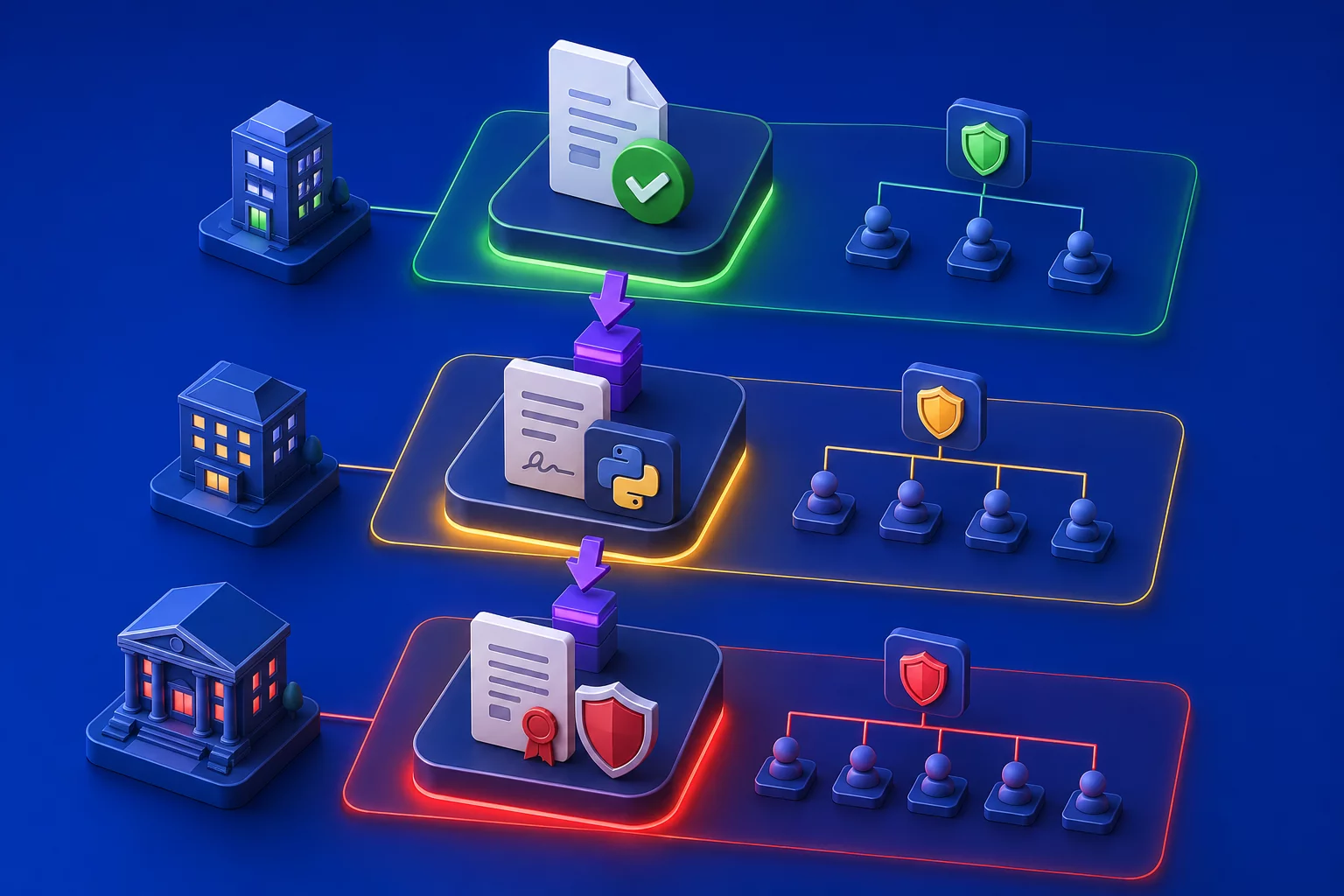
Три категории задач и три уровня проверки: не нужно всё проверять с одинаковой интенсивностью.
Если вы финансовый директор или главбух с командой, настройка индивидуальной системной инструкции это только первый шаг. Второй — создать командный протокол, чтобы все сотрудники работали по одним правилам.
Проблема без протокола. Один бухгалтер знает про тег [ПРОВЕРИТЬ] и расчёт в коде. Другой не знает и работает «как удобно». В итоге часть документов проходит проверку, часть нет, а вы как руководитель не можете отличить одно от другого, пока не появится ошибка.
Три элемента командного протокола:
Первый: общий список правил одним файлом. Три пункта максимум: всегда обезличивать данные перед загрузкой, все ссылки на нормативку помечать [ПРОВЕРИТЬ], все расчёты запрашивать в коде. Это файл в общем чате отдела, а не устная договорённость.
Второй: общая системная инструкция для всего отдела. Если команда использует ChatGPT Team или Claude Team (корпоративные тарифы), можно настроить системную инструкцию на уровне аккаунта организации. Тогда все сотрудники работают с одинаковой защитой по умолчанию, независимо от того, помнит ли каждый про настройку.
Третий: чек-лист как часть согласования документа. Если в вашей компании есть внутреннее согласование документов, добавьте в него одну строку: «проверен по чек-листу верификации ответа нейросети». Это создаёт культуру проверки, а не дополнительный бюрократический шаг.
Отдельный вопрос про корпоративные тарифы. ChatGPT Team и Claude Team юридически гарантируют не использовать ваши данные для обучения, дают администрирование доступов и журналирование. Это снижает риск утечки данных, но не отменяет системную инструкцию: утечка и галлюцинация это разные проблемы. Про обезличивание данных подробнее читайте в отдельной статье.
На курсе мы разбираем настройку командных протоколов под конкретные финотделы: производство, ритейл, оптовая торговля, онлайн-бизнес. Везде специфика разная, но структура протокола одинаковая.
Почему галлюцинации становятся дороже, а не дешевле со временем
Два года назад галлюцинацию было проще заметить. Модель писала «письмо Минфина от 1 января», которого явно не могло быть, или путала НДС и налог на прибыль в одном абзаце. Сейчас ситуация другая: ответы стали убедительнее, галлюцинации — менее заметными. Модель называет реальный номер статьи НК, но в редакции, которая уже не действует. Или реальный номер письма Минфина, но по другой теме. Это требует проверки, а не простого здравого смысла.
Параллельно входят в практику AI-агенты: цепочки задач, где нейросеть делает несколько шагов автономно. Один неверный факт на первом шаге передаётся на второй, потом на третий, и к концу цепочки ошибка уже встроена в структуру документа так, что выловить её труднее, чем в линейном ответе. На разборах я уже вижу кейсы: агент собирал информацию о компании-контрагенте из открытых источников, галлюцинировал один параметр (дата регистрации), и этот параметр дальше использовался в расчёте срока исковой давности. Финансист увидел проблему только в конце — через три шага расчёта.
Поэтому пять ошибок из этой статьи, протоколы проверки и чек-лист из 12 пунктов не устаревают. Их цена просто растёт. Начните с системной инструкции и промптов, которые заставляют модель показывать ход рассуждений. Всё остальное придёт с практикой.
Если хотите разобраться с нейросетями в финансовой работе системно — вот что мы делаем на курсе: подробно разбираем защиту от галлюцинаций, выстраиваем связку моделей под разные задачи, учим обезличиванию данных, строим AI-агентов для цепочек. Это 10 модулей, 800+ выпускников, реальные кейсы с цифрами. Курс — не теория про нейросети, а конкретные навыки под задачи финдира и главбуха.
FAQ: частые вопросы про галлюцинации нейросетей в финансовых данных
Что такое галлюцинация нейросети простыми словами? Галлюцинация это правдоподобный, но выдуманный ответ. Модель генерирует текст, предсказывая вероятное продолжение, а не проверяя факты в базе данных. Она называет несуществующее письмо Минфина с конкретным номером с той же уверенностью, что и реальное. Галлюцинация не ошибка программы и не обман, это фундаментальное свойство архитектуры. С каждым поколением моделей галлюцинируют реже, но не перестают.
Почему нейросеть уверенно называет несуществующие письма Минфина? Потому что обучена предсказывать вероятный текст, а не искать документы в базе. Когда вы просите назвать письмо Минфина по теме НДС при экспорте, модель строит текст, который выглядит как правильный ответ: номер, дата, структура цитаты. Это убедительно, потому что модель видела тысячи похожих текстов при обучении. Что она не может, так это открыть КонсультантПлюс и проверить. Поэтому любую ссылку на нормативку проверяем сами.
Как проверить, что нейросеть не выдумала цифры в расчёте? Два способа. Первый: попросить считать в коде Python. Тогда модель запускает настоящий интерпретатор, а не угадывает результат. Второй: задать тот же расчёт с другими числами и проверить логику по шагам. Признаки арифметической галлюцинации: слишком округлённый результат в сложном расчёте, отсутствие промежуточных шагов, несоответствие строк итоговой сумме.
Можно ли вообще доверять нейросети расчёт налогов? Расчёт можно, если работает через Python-код: это настоящий интерпретатор, арифметическая галлюцинация исключена. Ссылки на нормативку и ставки нельзя принимать без проверки никогда: модель называет устаревшую ставку с той же уверенностью, что и актуальную. Любой налоговый ответ с нормативными ссылками проверяется в КонсультантПлюс или на сайте ФНС.
Что такое метод двух моделей и как им пользоваться? Один и тот же вопрос задаётся двум разным моделям, например GPT-5.5 и Claude Sonnet 4.6. Если ответы совпадают по цифрам и ссылкам, вероятность галлюцинации ниже. Если ответы расходятся, это сигнал: идём в первоисточник. Метод особенно ценен для спорных нормативных вопросов и нестандартных налоговых ситуаций.
Когда нейросеть галлюцинирует чаще всего? Пять триггеров: вопросы по нормативке с требованием конкретных реквизитов документов, расчёты на больших таблицах без требования кода, вопросы о свежих изменениях законодательства (последние несколько месяцев), вопросы вне основной зоны обучения, и случаи, когда модели не хватает данных, но она не говорит об этом прямо.
Как настроить системную инструкцию против галлюцинаций в ChatGPT и Claude? В ChatGPT: Settings — Personalization — Custom Instructions, текст системной инструкции в поле «How would you like ChatGPT to respond?». В Claude: открыть Project, кнопка Custom Instructions, вставить текст. Настраивается один раз, работает во всех чатах проекта. По моей практике частота галлюцинаций по нормативке после этой настройки падает примерно в три раза.
Что делать, если нейросеть уже дала ошибочные данные, которые попали в документ? Три шага. Первый: остановить использование этого фрагмента до проверки. Второй: проверить каждую цифру и ссылку в первоисточнике. Третий: если документ ушёл, оценить риски и при необходимости направить корректировку. На будущее: ввести чек-лист из 12 пунктов перед каждой подписью. Прошлое не переиграть, но работать с системой проверки можно с сегодняшнего дня.
Что делать дальше: от разовых проверок к системе
Галлюцинации не исчезнут. Более новые модели 2026 и 2027 годов будут галлюцинировать реже, но не перестанут. Параллельно входят в практику финдира AI-агенты: там одна галлюцинация на входе запускает цепочку из 5-10 шагов, и разобраться, где именно ошибка, труднее, чем в одном ответе. Навык выявления галлюцинаций со временем становится дороже, а не дешевле.
Эта статья даёт базу: пять типов, 10 промптов, системную инструкцию, метод двух моделей и чек-лист из 12 пунктов. Реальная работа финансиста с нейросетями это система: правильные промпты под отрасль, связка моделей под разные задачи, обезличивание данных, AI-агенты для цепочек и безопасность данных. Об ошибках финансиста в нейросетях в целом и о том, как правильно строить промпты для бухгалтерии, есть отдельные разборы.
На курсе «AI-навыки финансиста» онлайн-школы «Финансовый директор | Мастер CFO» эта система собрана целиком: 10 модулей, 800+ выпускников, диплом установленного образца с лицензией, налоговый вычет 13%. Я веду курс лично, разбираю кейсы учениц на эфирах, чат поддержки работает 6 месяцев после выпуска.
Записаться на курс «AI-навыки финансиста»
Наши каналы
Присоединяйтесь к сообществу финансистов, которые уже работают с нейросетями:
- Telegram @findir_pro — 45 000 подписчиков, ежедневные разборы, промпты, кейсы из практики финдиров и главбухов
- «АИ с Софьей и Натали» — 13 000 подписчиков, новости AI, разборы инструментов, честные тесты моделей
- MAX-канал «Финансовый директор» — 5 000+ участников, закрытые материалы и разборы только для подписчиков канала
Об авторе
Натали Васильева. Эксперт по нейросетям и продюсер онлайн-школы «Финансовый директор | Мастер CFO» (основатель школы — Софья Бурцева). С нейросетями в работе финансиста с февраля 2023 года. Через курс «AI-навыки финансиста» прошли 800+ финансистов, главбухов и финдиров. Веду Telegram-канал @findir_pro (45 000 подписчиков) и канал «АИ с Софьей и Натали» (13 000 подписчиков). Личный набор: ChatGPT Plus, Claude Pro, Gemini Advanced, DeepSeek, YandexGPT.