AI для финансиста
5 ошибок финансиста в нейросетях: что мешает экономить 12 часов

Финансист пишет «проанализируй отчёт», получает три экрана общих фраз, переспрашивает дважды, в итоге делает руками и решает, что нейросеть для серьёзных задач не годится. Такую ситуацию я вижу каждую неделю на разборах с ученицами курса. По данным 800+ учениц, прошедших через мой курс, финансист теряет до 12 часов в неделю — и четыре ошибки из пяти это не слабая модель, а неправильная постановка задачи. В этой статье разбираю пять главных ошибок: размытый промпт, отсутствие контекста, незаданный формат, слепая вера в галлюцинации и загрузка данных без обезличивания. Даю 12 готовых промптов-антидотов, три кейса с цифрами и сравнение GPT-5.5, Claude Sonnet 4.6, Gemini 2.5 и DeepSeek V3.2 по состоянию на 29 мая 2026 года. Я Натали Васильева, продюсер онлайн-школы «Финансовый директор | Мастер CFO», с нейросетями в работе финансиста с февраля 2023 года.
Почему финансист теряет 12 часов в неделю на нейросетях
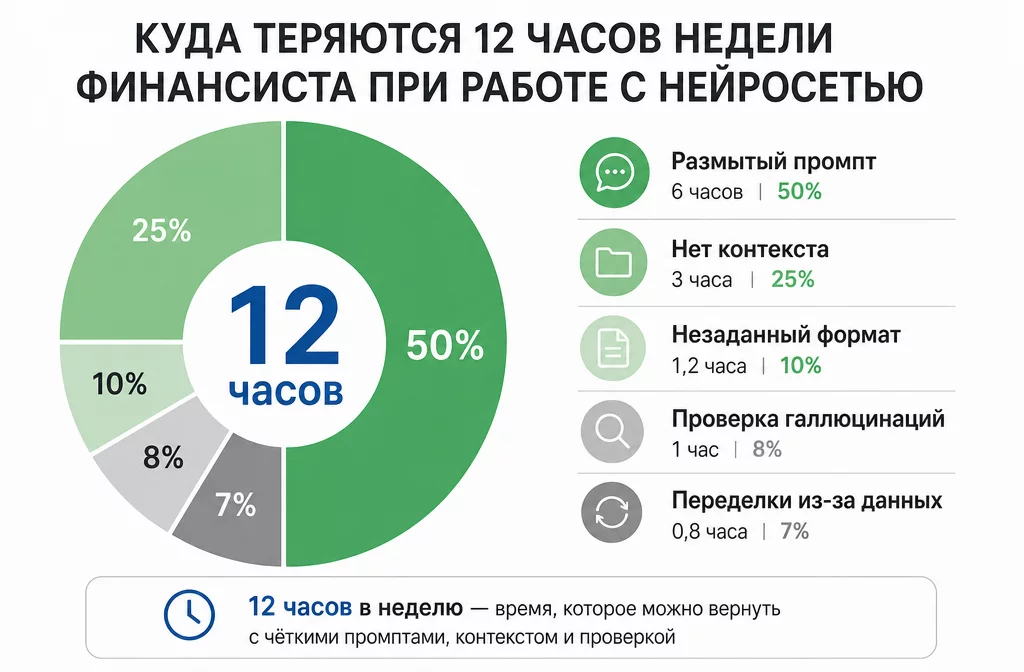
Большая часть потерянного времени уходит не на саму работу нейросети, а на переделку из-за размытой постановки задачи.
Прямой ответ: время утекает не на ответах модели, а на их переделке. Финансист с 10-15 годами опыта смотрит на экран, читает ответ нейросети и понимает, что результат — общая теория из учебника, не про его компанию и не в нужном формате. Переспрашивает, получает чуть конкретнее, переделывает таблицу руками — в итоге решает, что «серьёзные задачи быстрее сделать самой». На деле он несколько раз поставил плохой вопрос, а модель честно на него ответила.
На разборах с ученицами я систематически смотрю, на что уходит время в работе с AI. Картина почти всегда одинаковая. Большая часть потерь это размытые промпты, на которые модель отвечает в общих чертах. Следующий по частоте источник — отсутствие контекста: ответ правильный в принципе, но бесполезный для конкретной компании. Оставшееся делят незаданный формат (получили простыню вместо таблицы), проверка галлюцинаций после того, как поверили цифрам, и переделки из-за того, что данные пришлось грузить заново после правок.
Складывается это в те самые 12 часов в неделю. Финдир тратит их на цикл «спросил, не то, переспросил, доделал руками» вместо того, чтобы один раз поставить задачу правильно и получить результат с первого захода. Все пять ошибок системные, их видно, и каждая лечится конкретным приёмом, а не сменой модели.
Я специально не начинаю с «какую нейросеть выбрать». Это вторичный вопрос. Самый дорогой ChatGPT с плохим промптом проигрывает бесплатному DeepSeek с хорошим. Поэтому дальше идём не по моделям, а по ошибкам.
Что такое ошибка в нейросети и почему это почти всегда вина не модели
Ошибка в нейросети для финансиста это неверный, неполный или бесполезный результат, который пришлось переделывать. Ключевое слово «переделывать»: если ответ пришлось выкинуть, значит где-то была ошибка. И в четырёх случаях из пяти эта ошибка на стороне человека, а не модели.
Если виновата модель, стратегия одна: менять и ждать, пока выйдет умнее. Если виноват промпт, рычаг у вас в руках прямо сейчас: научиться ставить задачу и получать результат сегодня, на той модели, что уже есть.
Языковая модель — буквальный исполнитель: она отвечает на то, что написали, а не на то, что имели в виду. Сказали «напиши про НДС» получите учебник для студента. Сказали «ты налоговый консультант, объясни главбуху производства момент возникновения НДС при экспорте в 2026 году, в виде таблицы из трёх колонок» получите рабочий материал.
Пять ошибок, которые я разбираю дальше, идут по логике постановки задачи и работы с результатом:
- Промпт. Размытая формулировка без роли, задачи и деталей.
- Контекст. Модель не знает ничего о вашей компании, потому что вы не рассказали.
- Формат. Вы не сказали, в каком виде нужен ответ, и получили не то.
- Галлюцинации. Вы поверили цифрам и ссылкам, которые модель выдумала.
- Обезличивание. Вы загрузили чувствительные данные в публичный сервис.
Ошибки 1-3 случаются на этапе постановки задачи и стоят времени. Четвёртая — на выходе: неверное решение или штраф. Пятая — из зоны безопасности: утечка данных и репутационный ущерб. Разбираем по порядку.
Ошибка 1. Размытый промпт: почему «напиши про НДС» не работает
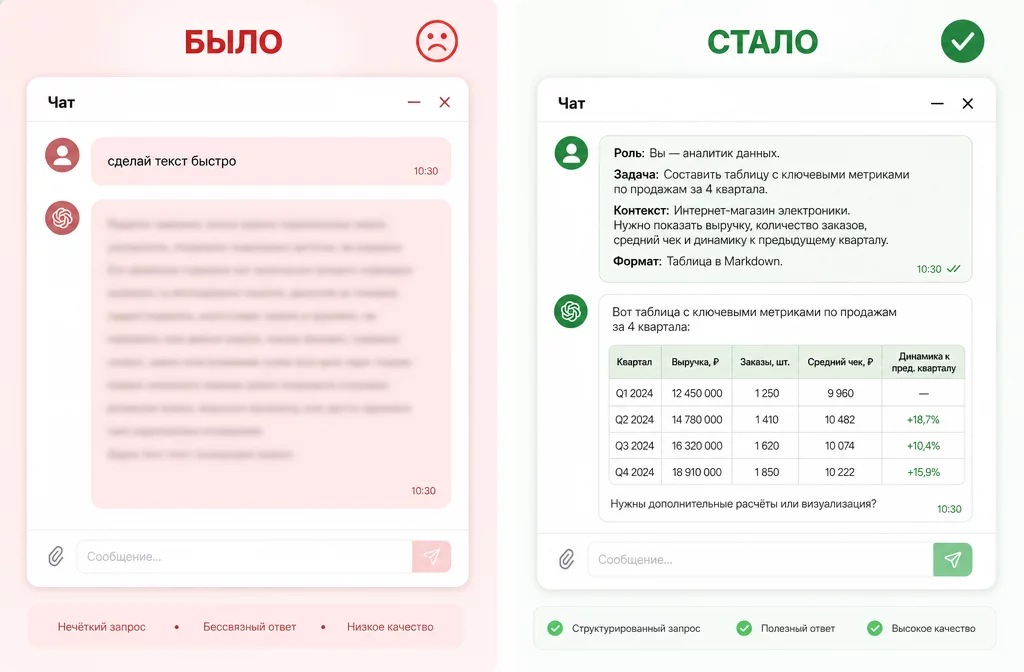
Один и тот же вопрос: слева промпт из трёх слов и вода в ответе, справа промпт-каркас и готовый рабочий результат.
Это ошибка номер один по частоте и по цене. Размытый промпт это запрос из нескольких слов без роли, задачи, контекста и формата: «проанализируй отчёт», «помоги с бюджетом», «что не так с этим договором». Модель отвечает ровно настолько же размыто, и начинается цикл переделок.
Почему так происходит. Нейросеть не знает, кто вы, для чего вам ответ и на каком уровне. На запрос «расскажи про дебиторку» она выберет усреднённый уровень: что-то между постом для блога и параграфом из учебника. Для финдира с 10 годами опыта это бесполезно. Модель не виновата, она не телепат.
Хороший промпт для финансовых задач состоит из пяти частей. Я называю это каркасом, мои ученицы держат его в заметке и достают под каждую новую задачу:
Промпт-каркас финансиста (антидот к ошибкам 1, 2, 3, 4)
1. РОЛЬ. Ты [кто], у тебя 10+ лет опыта в [отрасль/функция].
2. ЗАДАЧА. [Один глагол + объект]: проанализируй / составь / найди / сравни.
3. КОНТЕКСТ. Компания [тип], отрасль [какая], период [какой].
Раньше это делали так: [как]. Результат нужен для [кого].
Прикладываю [файл/таблицу/текст].
4. ОГРАНИЧЕНИЯ.
- используй только данные из приложения, не додумывай;
- если данных не хватает, прямо так и пиши;
- если нужен расчёт, считай в коде на Python и покажи ход;
- русский язык, деловой стиль, без англицизмов.
5. ФОРМАТ. Ответ в виде [таблица из N колонок / список из N пунктов /
текст до N слов]. В конце короткий вывод 2-3 предложения.Сравните два запроса на одну задачу. Плохой: «посмотри договор аренды, всё ли там нормально». Хороший:
Промпт. Экспресс-аудит договора аренды (хороший вариант)
Ты юрист по коммерческой недвижимости и финансовый контролёр
с 10+ лет практики. Проверяешь договор глазами арендатора.
Задача: найди в договоре пункты, финансово рискованные для арендатора.
Контекст: арендуем помещение под пекарню, 120 кв.м, Москва, срок 5 лет.
Прикладываю обезличенный текст договора.
Сфокусируйся на:
- индексация ставки (частота, ограничение, по какому индексу);
- условия одностороннего расторжения и штрафы;
- обеспечительный платёж (возврат, удержания);
- кто платит за ремонт и неотделимые улучшения;
- скрытые расходы (эксплуатационные, парковка, реклама).
Ограничения: используй только текст договора, не додумывай.
Если пункт сформулирован двусмысленно, прямо отметь это.
Формат: таблица из 4 колонок (пункт договора, цитата, риск,
рекомендация). Под таблицей вывод 3-4 предложения: подписывать,
торговаться или нет.Разница в результате колоссальная. Первый промпт даёт «в целом договор стандартный, обратите внимание на сроки». Второй даёт таблицу из 8-12 строк, с которой можно идти к арендодателю торговаться. Время на оба промпта одинаковое, минута на набор. Только второй не надо переделывать.
Типовые проявления ошибки 1:
- Запрос из 3-5 слов без роли и формата. Лечится каркасом.
- Несколько разных задач в одном промпте («проанализируй, составь таблицу и напиши письмо»). Модель делает всё поверхностно. Правило: одна задача, один промпт.
- Вежливость вместо конкретики. «Пожалуйста, не мог бы ты помочь мне разобраться» это слова, которые не несут задачи. Модели не нужна вежливость, ей нужны роль, задача, формат.
Отдельно скажу про психологию. Финансисты часто сопротивляются длинным промптам: «зачем писать абзац, если можно три слова». Логика понятна, но она ошибочна. Минута на структурный промпт экономит десять минут на переделках и доводках. Это та же инвестиция, что описать задачу подрядчику в техзадании, а не на словах в коридоре. Чем точнее вход, тем меньше итераций на выходе. На дистанции недели разница между «трёхсловными» и «каркасными» промптами это несколько свободных часов.
И последнее по ошибке 1. Промпт не обязан быть идеальным с первого раза, его можно собирать прямо в чате. Напишите черновую формулировку, посмотрите ответ, добавьте недостающее: «добавь роль налогового консультанта», «теперь в формате таблицы». Модель держит контекст диалога, поэтому достраивать промпт репликами быстрее, чем переписывать с нуля.
Практический приём, который экономит время на дистанции: когда формулировка сработала — сохраните промпт в заметку. Через месяц у вас будет личная библиотека под конкретные задачи, и хороший промпт для «разбора договора аренды» или «поиска аномалий в выгрузке» не нужно каждый раз писать заново.
Ошибка 2. Нет контекста: почему модель отвечает «вообще», а не про вашу компанию
Вторая по частоте ошибка. Промпт может быть структурным, с ролью и форматом, но если в нём нет контекста про вашу ситуацию, ответ будет правильным «в принципе» и бесполезным на практике. Контекст это то, что превращает учебник в консультацию.
Простой пример. Запрос «как оптимизировать дебиторку» даст десять общих советов из любой статьи: вводите кредитные лимиты, считайте оборачиваемость, работайте с просрочкой. Всё верно и всё мимо, потому что модель не знает вашу специфику. Теперь добавим контекст:
Промпт. Работа с дебиторкой (с контекстом)
Ты финансовый директор с 10+ лет опыта в оптовой торговле стройматериалами.
Контекст: оптовая база, 60 постоянных клиентов, средний чек 400 тыс. ₽,
отсрочка платежа 30-45 дней. Дебиторка выросла за полгода с 12 до 19 млн ₽
при той же выручке. Три клиента дают 40% оборота и хронически платят
с просрочкой 15-25 дней. Сезон пик с апреля по сентябрь.
Задача: предложи план снижения дебиторки на 25% за квартал
без потери трёх ключевых клиентов.
Ограничения: учитывай, что давить на крупных клиентов рискованно,
они уйдут к конкуренту. Используй реалистичные для РФ инструменты.
Не предлагай факторинг как единственное решение, разбери варианты.
Формат: таблица из 3 колонок (мера, эффект на дебиторку, риск).
Отдельно 3 скрипта переговоров с ключевым клиентом о сокращении отсрочки.Второй промпт даёт план, который можно нести собственнику. Первый даёт текст, который собственник прочитает и спросит «и что мне с этим делать». Контекст это и есть ответ на этот вопрос.
Что входит в контекст для финансовых задач:
- Тип и размер бизнеса. Производство, торговля, услуги, онлайн-школа. Выручка, число сотрудников, число клиентов.
- Отрасль и регион. Решения для Москвы и для региона разные, для опта и розницы разные.
- Период и динамика. Что было раньше, что изменилось, какой тренд.
- Для кого результат. Собственник, инвестор, налоговая, команда. Уровень и формат разные.
- Что уже пробовали. Чтобы модель не предлагала то, что не сработало.
Отдельная разновидность ошибки 2 это контекст-мусор. Финансист грузит в модель 20 файлов разного формата и пишет «разберись». Модель тонет в шуме и выдаёт средний ответ. Контекст должен быть релевантным, а не объёмным. Лучше один чистый файл с описанием колонок, чем десять сырых выгрузок.
Длинный контекст это сильная сторона современных моделей: у Gemini 2.5, GPT-5.5 и Claude Sonnet 4.6 окно до 1 миллиона токенов, у DeepSeek V3.2 до 128 тысяч. Но окно надо заполнять смыслом, а не мусором. Грузим то, что относится к задаче, и описываем структуру: «в приложении выгрузка из 1С, 28 000 строк, колонки такие-то».
Ещё один приём против ошибки 2 это постоянный контекст. У всех ведущих моделей есть память или системные инструкции, куда один раз вписываются базовые вводные про вашу компанию: отрасль, размер, специфика учёта, как устроена управленческая отчётность. Тогда в каждом новом чате не нужно объяснять заново, модель уже «знает» ваш бизнес на уровне фона. В это поле я советую положить роль по умолчанию, отрасль и две-три ключевые особенности. Чувствительные цифры туда не пишем, только нейтральный контекст.
Ошибка 3. Не задан формат: почему вы получаете простыню вместо таблицы
Третья ошибка дешевле первых двух по последствиям, но бьёт по времени каждый день. Вы получаете верный по смыслу ответ, но в неудобном виде: сплошной текст вместо таблицы, абзацы вместо списка, развёрнутые рассуждения вместо короткого вывода. Дальше полчаса вручную раскладываете это по ячейкам.
Модель по умолчанию отвечает прозой, потому что её так обучали: она языковая, текст её родная стихия. Таблицы, списки, JSON, готовые формулы для Excel она тоже умеет, но только если попросить. Не попросили получите эссе.
Финансисту почти всегда нужен структурированный вывод. Поэтому формат указываем явно и конкретно:
Примеры точной постановки формата
- «Ответ в виде таблицы из 4 колонок: статья, факт, план, отклонение в %.»
- «Список из 7 пунктов, каждый начинается с глагола, по одной строке.»
- «Готовая формула для Google Sheets, которую можно вставить в ячейку.»
- «Текст письма поставщику до 150 слов, деловой тон, каждое предложение — конкретное действие или условие.»
- «JSON со структурой: {контрагент, сумма, дата, тип_аномалии}.»
- «Краткий вывод в 3 предложения: что делать, риск, срок.»Маленький приём, который экономит часы: просите ответ сразу в том формате, в котором будете его использовать. Если данные пойдут в Excel, просите таблицу или формулу. Если в письмо собственнику, просите готовый текст нужной длины и тона. Если в презентацию, просите структуру по слайдам. Модель отдаст готовый кусок, который вставляется без переделки.
Ещё одна частая беда это длина ответа. Финансист задаёт короткий вопрос и получает три экрана текста, в которых тонет суть. Лечится одной фразой в промпте: «коротко, до 200 слов» или «только вывод, без объяснений». И наоборот, если нужна глубина, просим «разверни подробно, с примерами». Модель подстраивается под заданную длину.
Формат это не косметика. Когда ответ приходит в готовом виде, исчезает целый класс ручной работы: копирование по ячейкам, переписывание под нужный тон, сокращение простыни. Это та самая экономия, ради которой нейросеть и нужна.
Ещё одна мелочь, которая бьёт по времени регулярно: не указаны язык и валюта. Модель отвечает с долларами или кривым переводом с английского. Одна строка в блоке ограничений — «русский язык, суммы в рублях, деловой стиль» — снимает это полностью.
Ошибка 4. Слепая вера в галлюцинации: почему нейросеть врёт уверенно
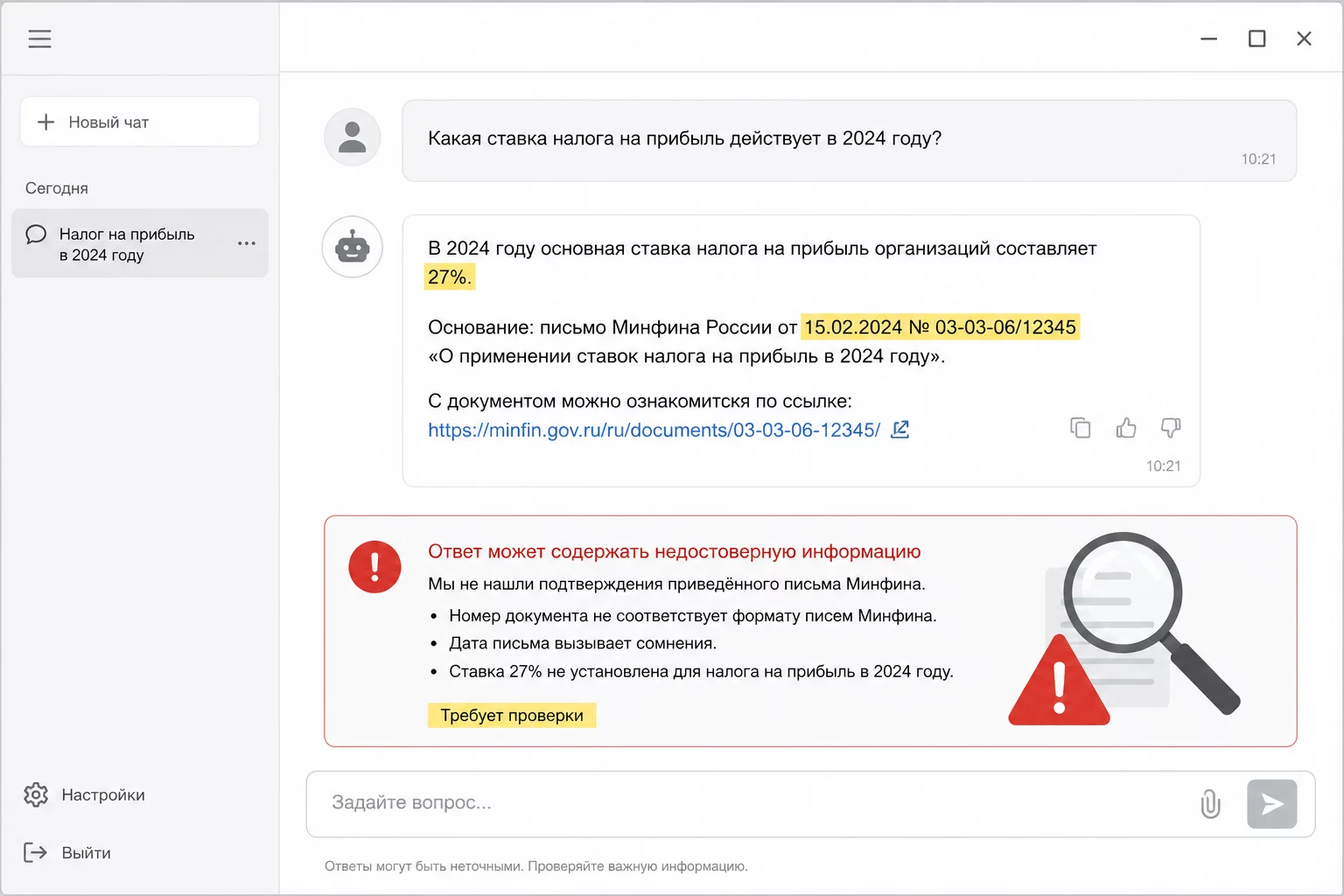
Галлюцинация выглядит убедительно: модель называет номер письма Минфина и статью НК с той же уверенностью, что и верные факты.
Это самая опасная ошибка, потому что её цена не время, а неверное решение, штраф или подставленный собственник. Галлюцинация это когда модель выдаёт правдоподобный, но выдуманный факт: несуществующее письмо Минфина, неверную ставку налога, ошибочную сумму в расчёте, придуманный пункт закона. И делает это с той же уверенностью, что и верные ответы.
Главное, что нужно понять: галлюцинация это не баг, который однажды починят. Это свойство технологии. Языковая модель устроена так, что всегда генерирует наиболее вероятное продолжение текста. Она физически не может ответить «я не знаю» по умолчанию, её к этому надо принудить. Поэтому на вопрос «какое письмо Минфина регулирует этот вычет» она с радостью назовёт номер и дату, даже если такого письма нет.
Два типа галлюцинаций, опасных для финансиста:
Фактические. Ссылки на нормативку, ставки, реквизиты, даты, номера законов. Модель обучена на данных прошлого и не знает изменений последних месяцев. Она уверенно сошлётся на отменённое письмо или ставку, которая поменялась. Любую норму проверяем в КонсультантПлюс или Гаранте, без исключений.
Арифметические. Это менее очевидно и потому коварнее. Модель не считает, она предсказывает похожий на ответ текст. На «посчитай НДС с 1 240 000» она выдаст правдоподобное число, которое может быть неверным. На таблице из 200 строк ошибки в суммах и процентах накапливаются незаметно.
Лечение арифметических галлюцинаций простое и почти стопроцентное: заставляем модель считать в коде.
Промпт. Принудительный расчёт в коде (антидот к арифметике)
Ты финансовый аналитик с 10+ лет опыта.
Задача: рассчитай показатели по приложенной таблице.
ВАЖНО: не считай в уме. Для всех расчётов пиши и выполняй код
на Python, показывай ход вычислений. Если в данных есть пропуски
или нечисловые значения, отдельно укажи это и не подставляй
выдуманные числа.
Прикладываю таблицу: [данные].
Посчитай: выручку по месяцам, рентабельность по продуктам,
динамику в % к прошлому периоду.
Формат: таблица с результатами + блок с кодом расчёта,
чтобы я мог проверить логику.Против фактических галлюцинаций работает системная инструкция. У chatgpt.com это «Custom instructions», у Gemini «Saved info», у Claude — поле «Project instructions» в разделе Projects (кнопка «Add custom instructions» в новом проекте). Вписываем один раз, действует на все чаты:
Системная инструкция против галлюцинаций (вставить один раз)
Ты обязан давать только проверенные данные. Если ты не уверен
в факте на 90 процентов, прямо пиши «не уверен» или «нужно проверить
в первоисточнике». Не выдумывай номера писем, статей, ставки и даты.
Не подгоняй цифры под красивый вывод. Любую ссылку на нормативку
(НК, письма Минфина, ФНС) помечай тегом [ПРОВЕРИТЬ В КОНСУЛЬТАНТПЛЮС],
потому что обучающие данные могут быть устаревшими. Если задача
требует расчёта, считай в коде и показывай ход.По моей практике с ученицами курса, в начале работы с нейросетями встречается 15-20 типовых галлюцинаций по нормативке на каждые 10 запросов про налоги и договоры. После установки такой системной инструкции и перехода на расчёт в коде в тех же задачах остаётся 2-3 — то есть убирается примерно 8 из 10. Оставшееся ловит финальный фильтр, и этот фильтр вы. Всё, что идёт собственнику, в налоговую, инвестору или в договор, проверяется человеком. Нейросеть не заменяет вашу подпись и вашу ответственность.
Ещё один рабочий приём это перекрёстная проверка. Один и тот же спорный вопрос задаём двум разным моделям, например Claude и GPT-5.5. Если ответы расходятся, это сигнал, что тема скользкая и нужен первоисточник. Если совпадают, уверенности больше, но первоисточник по нормативке всё равно смотрим.
Ошибка 5. Данные без обезличивания: чем рискует финансист
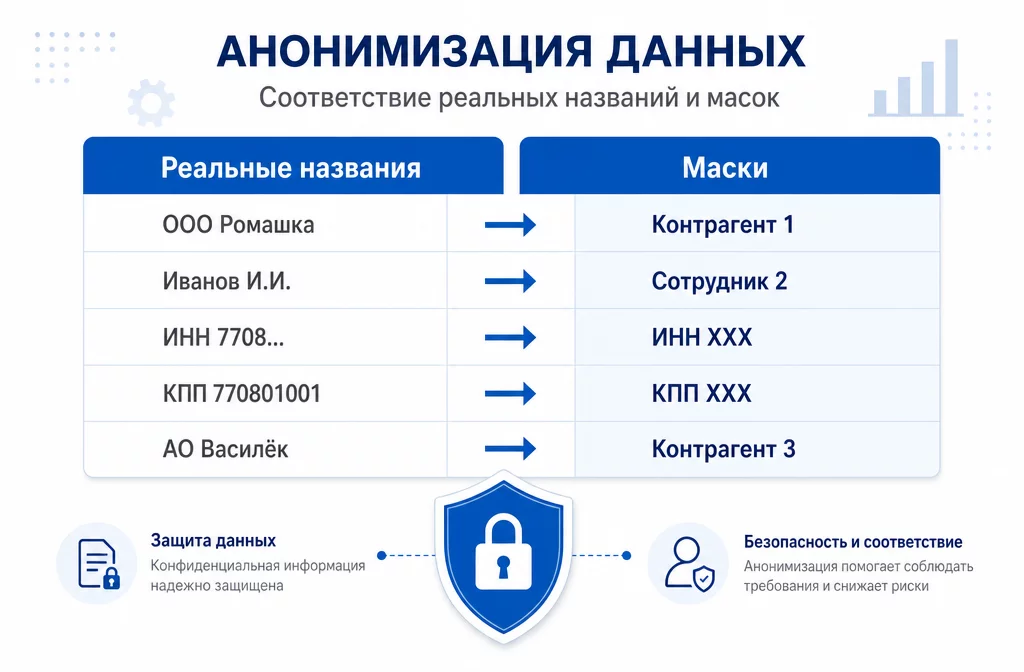
Справочник-мэппинг: две колонки, реальное название и маска. Прогон через автозамену занимает 3-5 минут на сессию.
Пятая ошибка стоит особняком: её цена не переделка и не неверный расчёт, а утечка коммерческой и персональной информации. Финансист берёт реальную выгрузку из 1С, договор с реальным контрагентом или зарплатную ведомость и грузит в публичную нейросеть как есть. Дальше эти данные уходят на серверы за пределами российского контура и могут попасть в обучающую выборку.
Прямой ответ: данные перед загрузкой в публичную нейросеть обезличиваем всегда, а документы под NDA, банковскую и коммерческую тайну не грузим вообще. Это не паранойя, это базовая гигиена, такая же как не оставлять пароль на стикере.
Что именно нельзя отправлять в публичную модель в исходном виде: реальные названия компаний и контрагентов, ИНН, номера счетов и договоров, ФИО сотрудников и физлиц, зарплаты по именам, банковскую тайну, данные под NDA, всё, что относится к M&A и закрытым сделкам.
Инструмент обезличивания это справочник-мэппинг. Таблица из двух колонок: реальное название и маска. Перед загрузкой прогоняете документ через автозамену, после ответа возвращаете настоящие названия обратно.
Промпт. Помощник для обезличивания текста
Ты помощник по защите данных. Я даю текст документа.
Задача: найди в тексте все данные, которые нельзя отправлять
в публичный сервис, и предложи маски для замены.
Найди и выпиши таблицей: названия компаний, ФИО, ИНН, номера счетов
и договоров, телефоны, адреса, email, конкретные бренды и продукты.
Формат: таблица из 2 колонок (что найдено, предлагаемая маска).
Маски делай в формате «Контрагент 1», «Сотрудник 2», «ИНН XXX».
Сам текст не переписывай, только составь справочник для автозамены.Три уровня обезличивания под разные задачи:
| Уровень | Что меняем | Когда применять |
|---|---|---|
| Минимальный | Имена и реквизиты на маски, суммы оставляем | Проверка формулировки в одном акте, короткая переписка, низкий риск |
| Средний | Имена, реквизиты, счета, ФИО физлиц; суммы округляем до сотен тысяч | Разбор договоров, выгрузки из 1С, записки к ОДДС, большинство задач |
| Параноидальный | Меняем всё, отрасль на смежную, суммы умножаем на коэффициент 0,7 или 1,3 | NDA, M&A, чувствительные сделки, зарплатные данные |
Вторая линия защиты это настройки самого сервиса. Почти у всех моделей есть переключатель «не использовать мои данные для обучения»: у ChatGPT в Data Controls, у Gemini в Activity, у Claude обучение на данных пользователей по умолчанию отключено. Включаем везде. Но это не отменяет обезличивание, а дополняет его.
Для команд от двух человек разумный вариант это корпоративные тарифы (ChatGPT Team, Gemini Workspace, Claude Team), где провайдер юридически гарантирует не использовать данные для обучения. Это снижает риск, но и здесь чувствительные документы под NDA лучше держать вне публичного облака.
Почему это не «перестраховка». В России действует закон о персональных данных (152-ФЗ), и ответственность за их утечку лежит на компании. Зарплатная ведомость с ФИО, паспортные данные, реквизиты клиентов-физлиц это персональные данные. Отправив их в публичную нейросеть с серверами за рубежом, вы формально совершаете трансграничную передачу без оснований. Для финансиста это не абстрактный риск, а прямая зона ответственности, по которой в 2026 году штрафы выросли. Обезличивание снимает большую часть этого риска, потому что замаскированные данные перестают быть персональными.
Частый вопрос учениц: «а что если я уже полгода грузила всё как есть, что теперь делать». Ответ спокойный: прекратить, завести справочник, в настройках сервиса включить отказ от обучения и при возможности удалить историю чатов с чувствительными данными. Прошлое не переиграть, но дальше работать правильно можно с сегодняшнего дня.
Если хочешь увидеть, как я ставлю задачу нейросети и за 15 минут получаю готовую таблицу аномалий из выгрузки 1С, с разбором промпта на экране, приходи на эфир «AI-практикум финдира». Показываю каркас промпта, обезличивание и проверку галлюцинаций на живых данных. 2 часа практики, регистрация открыта.
Какой промпт-каркас закрывает четыре ошибки из пяти
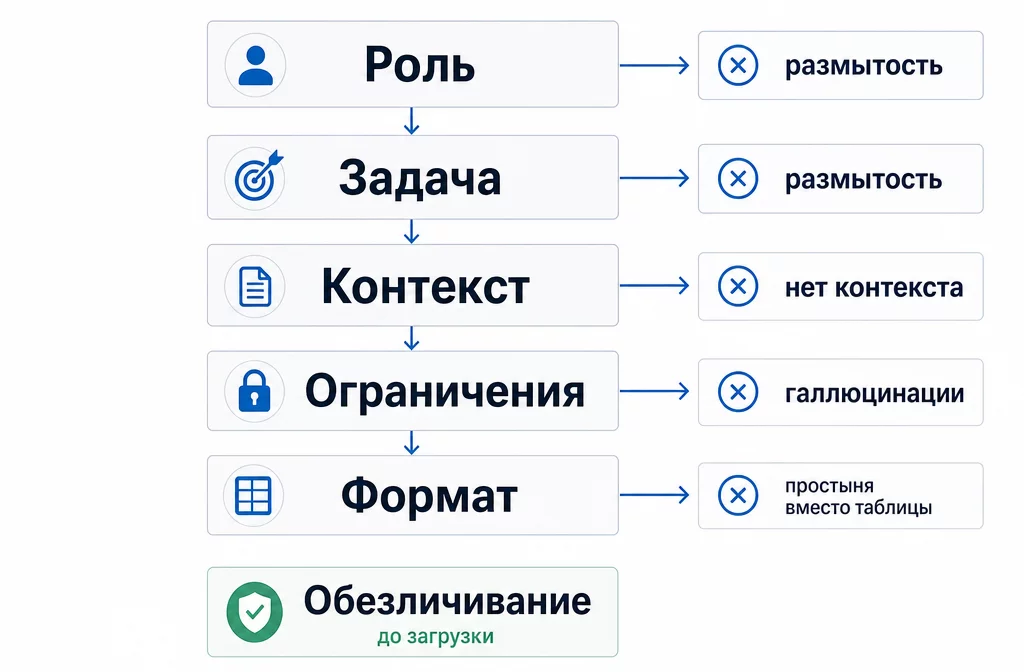
Пять блоков каркаса закрывают четыре ошибки из пяти. Пятую (обезличивание) делаем до загрузки документа.
Четыре ошибки из пяти закрывает один промпт-каркас. Это не магия, а дисциплина постановки задачи. Каждый блок бьёт по своей ошибке.
| Блок промпта | Какую ошибку закрывает | Что даёт |
|---|---|---|
| Роль с опытом | Ошибка 1 (размытость) | Модель отвечает на уровне эксперта, а не усреднённо |
| Задача одним глаголом | Ошибка 1 (размытость) | Один чёткий результат вместо «всего обо всём» |
| Контекст | Ошибка 2 (нет контекста) | Ответ про вашу компанию, а не «вообще» |
| Ограничения | Ошибка 4 (галлюцинации) | «Не додумывай», «считай в коде», «не уверен пиши» |
| Формат | Ошибка 3 (формат) | Готовая таблица или список, без ручной переделки |
Пятая ошибка, обезличивание, в каркас не входит, потому что делается раньше, на этапе подготовки документа. Поэтому полный цикл правильной работы такой: сначала обезличили данные, потом поставили задачу по каркасу, потом проверили результат глазами.
Чтобы каркас работал на автомате, я советую ученицам один раз настроить системную инструкцию (туда уходят роль по умолчанию и защита от галлюцинаций) и держать в заметке два-три шаблона под частые задачи. Тогда на постановку задачи уходит минута, а не пять, и переделок почти нет.
Важный нюанс про итеративность. Первый ответ модели это черновик, а не финал. Нормальная работа это диалог: «уточни вот этот пункт», «переделай таблицу, добавь колонку с риском», «слишком длинно, сократи до пяти строк». Финансисты, которые ждут идеального ответа с первого промпта и разочаровываются, теряют главное преимущество нейросети, скорость доработки. Доводить ответ репликами в чате быстрее, чем переписывать промпт с нуля.
Готовые промпты-антидоты для типовых задач финансиста
Ниже промпты под конкретные ситуации, в каждом уже зашиты защита от ошибок. Копируйте, подставляйте свои данные (обезличенные), используйте.
Промпт 1. Заставить модель задать уточняющие вопросы. Антидот к ошибкам 1 и 2: вместо ответа наугад модель сначала выясняет недостающее.
Ты финансовый консультант с 10+ лет опыта. Прежде чем отвечать
на мою задачу, задай мне 4-6 уточняющих вопросов, ответы на которые
тебе нужны, чтобы дать точный, а не общий ответ. Не отвечай на саму
задачу, пока я не отвечу на вопросы.
Задача: [впишите задачу].Промпт 2. Разбор управленческого отчёта. Контекст плюс жёсткий формат плюс расчёт в коде.
Ты финансовый директор с 10+ лет опыта в управленческом учёте.
Контекст: [тип бизнеса, отрасль, период]. Прикладываю обезличенный
P&L за [период], колонки: статья, факт, план.
Задача: проанализируй отклонения и найди проблемные зоны.
Считай отклонения в коде на Python, не в уме. Используй только данные
из таблицы, не додумывай. Если статья пустая, так и отметь.
Формат: таблица (статья, факт, план, отклонение ₽, отклонение %,
комментарий) + топ-3 проблемы списком + вывод в 3 предложения.Промпт 3. Поиск аномалий в выгрузке 1С. Контекст, перечень паттернов, формат таблиц.
Ты финансовый аналитик-аудитор с 10+ лет практики.
Прикладываю обезличенную выгрузку из 1С. Файл: [N] строк.
Колонки: дата, контрагент_маска, ИНН_маска, договор, сумма_₽,
статья_расходов, ЦФУ.
Задача: найди аномалии. Сфокусируйся на:
1. Задвоенные платежи (одинаковые контрагент + сумма + статья,
разница в датах до 3 дней).
2. Контрагенты с резким ростом оборота к среднему.
3. Округлённые до 100 тыс. суммы и платежи на новые счета.
4. Просрочки оплат на 30+ дней против прошлого квартала.
Считай в коде. Используй только данные из выгрузки, не додумывай.
Формат: 4 таблицы по 5-15 строк, под каждой вывод 2 предложения.Промпт 4. Черновик письма поставщику. Антидот к ошибке формата и к воде.
Ты финансовый менеджер. Напиши письмо поставщику с просьбой
сократить отсрочку оплаты с 45 до 30 дней в обмен на гарантию
объёма закупок. Тон деловой, уважительный, без давления.
Ограничение: до 150 слов, конкретное предложение в первом абзаце,
без вводных конструкций («в связи с вышеизложенным», «хотели бы
обратить ваше внимание»), деловой тон. Дай 2 варианта: помягче
и пожёстче.Промпт 5. Сравнение коммерческих предложений (TCO). Считаем эффективную стоимость, а не цену с лендинга.
Ты финансовый аналитик по закупкам с 10+ лет опыта в оценке
совокупной стоимости владения.
Прикладываю обезличенные данные по 5 КП на закупку [категория]:
цена за единицу, объём, условия оплаты (предоплата или отсрочка),
доставка, гарантия, срок поставки.
Задача: сравни по совокупной стоимости, а не по цене за единицу.
Стоимость денег считай по ставке 21% годовых. Считай в коде на Python.
Формат: таблица (поставщик_маска, цена, эффективная цена с учётом
отсрочки, доставка, итог, срок) + рекомендация в 3 предложения.Промпт 6. Объяснение сложного простым языком для собственника. Антидот к ошибке формата и уровня.
Ты финансовый директор, который умеет объяснять цифры собственнику
без финансового жаргона.
Задача: объясни, почему при росте выручки на 20% прибыль упала.
Контекст: [впишите свои причины: рост ФОТ, закупочных цен и т.д.].
Формат: 5 предложений простым языком, как для умного, но не
финансового человека. Без терминов EBITDA, маржинальность без
расшифровки. В конце один практический вывод.Промпт 7. Самопроверка ответа моделью. Заставляем модель критиковать собственный вывод.
Вот твой предыдущий ответ. Теперь побудь критиком: найди в нём
3 слабых места или возможных ошибки. Проверь, нет ли выдуманных
цифр, ссылок на нормативку без подтверждения, логических разрывов.
Если всё чисто, так и скажи. Если есть сомнения, перечисли,
что нужно проверить в первоисточнике.Промпт 8. Управленческий комментарий к ОДДС для собственника. Превращает таблицу движения денег в объяснение, понятное без финансового образования.
Ты финансовый директор с 10+ лет опыта в управленческом учёте.
Контекст: [тип бизнеса, отрасль]. Прикладываю обезличенный ОДДС
за [период]: три раздела — операционная, инвестиционная, финансовая.
Чистый денежный поток за период: [сумма].
Задача: напиши управленческий комментарий к ОДДС для собственника.
Он не финансист, термины ОДДС ему непривычны.
Сфокусируйся на:
- почему чистый денежный поток вырос / упал к прошлому периоду
и какой раздел внёс наибольший вклад;
- какие статьи выглядят нетипично и на что обратить внимание;
- что нужно решить в следующем квартале.
Ограничения: только данные из приложения, не додумывай.
Если раздела нет или данных не хватает, прямо напиши об этом.
Формат: три абзаца по разделам, 3-4 предложения каждый.
В конце вывод для собственника в 2 предложения: что хорошо
и что требует внимания. Без жаргона, простым языком.Промпт 9. Проверка формулы Excel/Sheets. Конкретная задача с понятным форматом.
Ты эксперт по Excel и Google Sheets. Вот моя формула: [вставьте].
Она даёт ошибку [какую] / неверный результат [какой ожидала].
Задача: объясни, в чём проблема, по шагам. Дай исправленный вариант
формулы, который можно вставить в ячейку. Если есть более простой
способ через другую функцию, предложи его отдельно.Промпт 10. Сводка по большому документу. Длинный контекст плюс защита от галлюцинаций.
Ты финансовый аналитик. Прикладываю обезличенный документ на [N] страниц
([что это: договор, отчёт, политика]).
Задача: сделай рабочую сводку для финдира.
Формат: 1) суть в 5 предложениях; 2) ключевые цифры таблицей
(только те, что есть в документе, без додумывания); 3) риски
и спорные места списком; 4) что проверить дополнительно.
Используй только текст документа. Если чего-то нет, пиши «в документе
не указано», не выдумывай.Промпт 11. Сценарный анализ. Контекст плюс расчёт в коде плюс формат сценариев.
Ты финансовый директор с 10+ лет опыта в финансовом планировании.
Контекст: [тип бизнеса, отрасль]. Прикладываю базовую финмодель.
Задача: посчитай 3 сценария: базовый, пессимистичный (выручка -25%,
расходы +10%), оптимистичный (выручка +20%). Считай в коде на Python.
Ограничения: используй только данные из приложенной модели, не додумывай.
Если данных для сценария не хватает, укажи, каких именно.
Формат: таблица по сценариям (выручка, расходы, EBITDA, чистая прибыль,
точка безубыточности). Под таблицей вывод: при каком сценарии бизнес
уходит в минус и что критично контролировать.Промпт 12. Подготовка к разговору с налоговой. С обязательной пометкой проверки нормативки.
Ты налоговый консультант с 10+ лет практики. Помоги подготовиться
к ответу на требование ФНС по [тема].
Задача: объясни, какую позицию занять, какие документы приложить,
на какие нормы опереться.
ВАЖНО: все ссылки на статьи НК и письма помечай тегом
[ПРОВЕРИТЬ], я перепроверю в КонсультантПлюс. Не выдумывай номера
и даты. Если не уверен в норме, прямо пиши об этом.
Формат: позиция в 3 предложениях + список документов + список норм
с пометками [ПРОВЕРИТЬ].Эти 12 промптов покрывают большую часть рутины финансиста. Сохраните их в отдельную заметку или папку, подставляйте свои обезличенные данные. Через неделю использования сформируется привычка, и плохие промпты уйдут сами.
Какая модель чаще ошибается: GPT-5.5, Claude, Gemini или DeepSeek
Прямой ответ: универсального «самого надёжного» нет, у каждой модели свой профиль ошибок. Дело не в том, какая модель умнее, а в том, какая ошибка для вашей задачи критичнее. Для сравнения я в мае 2026 года прогнала через все четыре модели одинаковый набор из 20 задач: анализ договора, поиск аномалий в выгрузке, расчёт сценариев, черновики писем и нормативные вопросы. Вот картина по состоянию на 29 мая 2026 года.
| Параметр | GPT-5.5 (ChatGPT) | Claude Sonnet 4.6 | Gemini 2.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| Профиль ошибок | иногда уверенно врёт цифры | реже всех выдумывает | путает падежи в редких терминах | бывает многословен |
| Длинные тексты, договоры | хорошо | отлично | средне | хорошо |
| Аналитика, аккуратность | хорошо | отлично | хорошо | хорошо |
| Расчёты в коде | да, сильно | да | да, сильно | да, показывает ход |
| Контекстное окно | до 1М | до 1М | до 1М | до 128К |
| Русский деловой язык | отлично | отлично | хорошо | хорошо |
| Ход рассуждения видно | по запросу | по запросу | по запросу | да, по умолчанию |
| Доступ из РФ | через средства доступа | через средства доступа | через средства доступа | проще всех |
| Цена | ≈$20/мес | ≈$20/мес | ≈$20/мес | дешевле, есть free |
| Где сильнее всего | универсал, агенты | аналитика, тексты | таблицы, 1М выгрузки | расчёты, цена |
Как читать эту таблицу под задачу:
- Длинный договор или большой текстовый отчёт. Беру Claude Sonnet 4.6, он аккуратнее всех в формулировках и реже выдумывает.
- Большая выгрузка из 1С с объёмными табличными данными. Беру Gemini 2.5 — у него сильный табличный движок и расчёты, — но описываю структуру колонок, иначе он тратит контекст на угадывание.
- Универсальная задача, агент, исследование. Беру GPT-5.5, но цифры из ответа перепроверяю, он бывает излишне уверен.
- Расчёт, где важно видеть ход, или ограничен бюджет. Беру DeepSeek V3.2, он показывает рассуждение по умолчанию и дешевле.
Важный вывод, который я повторяю на каждом потоке: смена модели не лечит ошибки постановки задачи. Размытый промпт даст вату в любой из четырёх моделей. Сначала каркас, потом выбор инструмента. Финансисту-одиночке на старте хватает одной подписки, на дистанции в 3-6 месяцев складывается связка из двух: одна для текстов и аналитики, вторая для таблиц и расчётов.
Отдельно про доступ из России. Сайты ChatGPT, Claude и Gemini напрямую из РФ не открываются, нужны специальные средства доступа, и каким способом подключаться, каждый решает сам с учётом задач и требований безопасности. Инструкций по обходу блокировок здесь нет, это не зона ответственности статьи. Оплату зарубежных подписок принимают только иностранные карты, поэтому их обычно оформляют через сервисы виртуальных карт или доверенного знакомого за рубежом. DeepSeek и российские модели (YandexGPT, GigaChat) в этом смысле проще: к ним доступ из РФ свободнее, а у YandexGPT и GigaChat данные остаются в российском контуре, что снимает часть вопросов с обезличиванием для нечувствительных задач. Для финансиста это аргумент держать в наборе хотя бы одну российскую модель под задачи, где важна локальность данных.
Кейсы: как три финансиста перестали терять часы
Три истории моих учениц с курса «AI-навыки финансиста». Имена обезличены, цифры реальные.
Кейс 1. Финдир производства: от воды к таблицам аномалий
Елена, финдир мебельного производства в Подмосковье, 180 сотрудников, 11 лет в профессии.
Точка А. Полгода «пользовалась ChatGPT», но забросила: «отвечает водой, проще руками». Промпты были такие: «проанализируй этот отчёт», «что не так с дебиторкой». Ответы общие, переделок много, разочарование. На ручной квартальный аудит реестра платежей уходило два дня.
Что сделали. На разборе мы переписали её промпты по каркасу: роль, контекст про мебельное производство, перечень паттернов аномалий, формат таблиц, расчёт в коде. Добавили системную инструкцию против галлюцинаций и обезличивание выгрузки через справочник.
Точка Б. Тот же квартальный аудит теперь занимает 2 часа вместо 16. За первый прогон по новому промпту нашла задвоенный платёж на 310 тысяч рублей и поставщика с системной просрочкой. Экономия 14 часов в квартал на одной этой задаче, плюс вернулось доверие к инструменту. «Оказалось, дело было не в нейросети, а в том, как я спрашивала».
Кейс 2. Главбух онлайн-школы: цена галлюцинации
Светлана, главбух онлайн-школы, 9 лет в профессии, команда из 4 бухгалтеров.
Точка А. Использовала нейросеть для вопросов по налогам и однажды чуть не отправила в ответе на требование ФНС ссылку на письмо Минфина, которое модель выдумала. Поймала случайно, когда не нашла письмо в КонсультантПлюс. Поняла, что несколько прошлых ответов уходили без проверки.
Что сделали. Поставили жёсткое правило: вся нормативка помечается тегом [ПРОВЕРИТЬ] и сверяется в первоисточнике. В системную инструкцию добавили запрет выдумывать номера и даты. Для расчётов налогов перешли на формат «считай в коде». Завели привычку перекрёстной проверки спорных вопросов на двух моделях.
Точка Б. Риск ушёл. Нейросеть осталась в работе как помощник для черновиков и расчётов, но каждый факт теперь проходит фильтр. Светлана оценивает экономию в 6-8 часов в неделю на черновиках писем, расчётах и сверках, при этом «без страха подставиться перед налоговой». Цена непойманной галлюцинации в её случае могла быть штрафом и репутацией.
Кейс 3. Финансовый менеджер торговой компании: безопасность данных
Дмитрий, финансовый менеджер оптовой торговой компании, 7 лет опыта.
Точка А. Активно гонял договоры и реестры через нейросеть, грузил как есть, с реальными контрагентами, ИНН и суммами. На вопрос про обезличивание отвечал «да кому эти данные нужны». После внутренней проверки безопасности в компании это стало проблемой: финансовые данные контрагентов уходили в публичный сервис.
Что сделали. Завели справочник-мэппинг на 60 постоянных контрагентов, настроили автозамену через Ctrl+H, включили в настройках сервисов отказ от обучения на данных. Договоры под NDA вывели из публичной модели полностью. Обезличивание заняло в процессе 3-5 минут на документ.
Точка Б. Скорость работы не упала, риск утечки снят. Служба безопасности согласовала использование нейросети при условии обезличивания. Дмитрий продолжил экономить свои 10 часов в неделю на разборе договоров и сравнении КП, но уже без риска для компании. «Три минуты на автозамену оказались самой дешёвой страховкой в моей жизни».
Чего нейросеть не сделает за финансиста: 5 границ
Чтобы ожидания были честными, разберу пять вещей, которые нейросеть не закрывает, и попытка переложить их на модель это тоже ошибка, шестая по счёту.
1. Не несёт ответственность. Подпись под отчётом, декларацией и управленческим решением ваша. Нейросеть это инструмент, а не сотрудник, с которого можно спросить.
2. Не видит юридические риски отрасли. Опасную формулировку в договоре, которая выстрелит через два года в вашей конкретной отрасли, модель не оценит. Юрист обязателен.
3. Не знает свежую нормативку. Модель обучена на данных прошлого. Изменения ставок, новые письма, отменённые нормы она не отслеживает в реальном времени. Первоисточник за вами.
4. Не понимает контекст вашего бизнеса полностью. Она знает то, что вы написали в промпте. Неявные договорённости, историю отношений с собственником, политику компании она не учитывает, пока вы это не дали.
5. Не считает без принуждения к коду. На сложной арифметике без «считай в Python» модель угадывает. Финальные цифры в отчётности проверяем сами.
Эти границы не отменяют пользу. Они задают правильную рамку: нейросеть это второй пилот, который берёт на себя рутину, черновики и первичную аналитику, а пилот это вы. В этой рамке 8-12 часов в неделю экономии реальны и безопасны.
Почему эти ошибки дорожают, а не дешевеют
Год назад ученица тратила 15 минут на проверку ответа по галлюцинациям, и ошибку было видно невооружённым глазом: модель писала «письмо Минфина от 1 января», которого явно не могло быть. Сейчас та же ученица тратит те же 15 минут, но ошибку теперь найти труднее: модель называет реальный номер статьи НК и правдоподобную дату, которых просто нет в актуальной редакции. Это и есть суть тренда: галлюцинации не исчезают, они становятся убедительнее. Параллельно входят в практику финдира AI-агенты: там одна размытая задача на входе запускает цепочку из 5-10 шагов, и разобраться, где именно ошибка, намного труднее, чем в одном ответе модели. Пять ошибок из этой статьи не устаревают. Их цена просто растёт.
FAQ: частые вопросы про ошибки в нейросетях
Работает ли мобильное приложение ChatGPT или Claude так же хорошо, как веб-версия? Для коротких задач: да. Для длинных документов, выгрузок и расчётов в коде лучше веб-версия: там проще загрузить файл, код выполняется в той же сессии и контекст не теряется при переключении. На телефоне удобно надиктовать черновик задачи, который потом доводите за компьютером.
Какой главный признак плохого промпта? В нём меньше трёх из пяти элементов: роль, задача, контекст, ограничения, формат. Запрос «проанализируй отчёт» содержит только задачу: модель не знает, кто вы, для кого результат и в каком виде он нужен.
Можно ли использовать нейросеть командой бухгалтерии, а не только лично? Да, и это удвоит эффект. Заведите общий документ с промптами под типовые задачи отдела, согласуйте правила обезличивания и единую системную инструкцию. Тогда не нужно объяснять каждому сотруднику с нуля: одинаковый каркас, одни правила защиты данных, предсказуемый результат. На корпоративных тарифах ChatGPT Team и Claude Team провайдер юридически гарантирует не использовать данные для обучения.
С чего начать, если раньше «не пошло»? С переписывания одного своего рабочего промпта по каркасу. Возьмите задачу, которую делаете еженедельно, и добавьте роль, контекст, ограничения, формат. Разница в первом же ответе обычно убеждает лучше любой статьи.
Чек-лист: перед отправкой результата собственнику или в налоговую
Промпт-каркас проверяется на входе. Этот чек-лист — на выходе: шесть вопросов, которые задаём перед тем, как подписать результат или отправить его дальше.
- Расчёты. Все цифры в ответе получены через код на Python, а не «угаданы» моделью?
- Нормативка. Все ссылки на НК, письма Минфина, ставки проверены в КонсультантПлюс или Гаранте?
- Данные. В финальном тексте нет реальных ИНН, ФИО, номеров счетов, коммерческих тайн?
- Проверка глазами. Вы прочитали итоговый материал целиком, а не просто скопировали ответ модели?
- Источники. Все выводы опираются на данные, которые вы передавали в задаче, а не додуманы моделью?
- Ответственность. Если результат идёт под вашей подписью или от имени компании: вы готовы за него отвечать?
Шесть галочек — и материал можно отправлять. Этот список закрывает ошибки 4 и 5 уже после того, как промпт отработал.
Что делать дальше, если хочется системы, а не одиночных промптов
Эта статья даёт каркас, 12 промптов и систему проверки. Но реальная работа финансиста с AI это не один приём, а система: связка моделей под разные задачи (ChatGPT, Claude, Gemini, DeepSeek, YandexGPT), свои промпты под отрасль, правильное обезличивание, AI-агенты, связка с 1С и Google Sheets, безопасность данных.
На курсе «AI-навыки финансиста» онлайн-школы «Финансовый директор | Мастер CFO» эта система собрана целиком: 10 модулей, 800+ выпускников, диплом установленного образца с лицензией, налоговый вычет 13%. Я веду курс лично, разбираю кейсы учениц на эфирах, чат поддержки работает 6 месяцев после выпуска. Вы перестаёте терять часы на переделки и начинаете экономить их системно.
Записаться на курс «AI-навыки финансиста»
Об авторе
Натали Васильева. Продюсер онлайн-школы «Финансовый директор | Мастер CFO». С нейросетями в работе финансиста с февраля 2023 года. Через мой курс «AI-навыки финансиста» прошли 800+ финансистов, главбухов и финдиров. Веду Telegram-канал @findir_pro (45 000 подписчиков), MAX-канал «Финансовый директор» (5 000+) и YouTube-канал онлайн-школы. Личный набор: ChatGPT Plus, Claude Pro, Gemini Advanced, DeepSeek, YandexGPT, GigaChat.