AI для финансиста
Как обезличить финансовые данные перед ChatGPT: 3 уровня защиты для NDA-документов

В 2026 году главный риск финансиста в работе с нейросетью это не плохой ответ, а слитые данные. Перед загрузкой в chatgpt.com финансовые данные обезличиваются всегда, а банковскую тайну и документы под жёстким NDA в публичное облако не отправляют вообще. В этой статье я разбираю обезличивание по системе трёх уровней защиты, которую применяю три года в работе с финансистами: 10 готовых промптов, шаблон справочника-мэппинга, разбор ст. 13.11 КоАП и три кейса с цифрами. Актуально по состоянию на 30 мая 2026 года.
Почему обезличивание данных в ChatGPT это не паранойя, а закон
За данные, ушедшие в нейросеть, отвечает финансист и его компания, а не OpenAI. Когда вы грузите в ChatGPT реестр с реальными ИНН, ФИО и суммами, вы передаёте персональные данные и коммерческую тайну на зарубежный сервер. Если эти данные утекут или их потребует регулятор, спрашивать будут с вас.
Российское регулирование персональных данных в 2026 году ужесточилось. Нарушения по ст. 13.11 КоАП оборачиваются для юрлиц штрафами, а с 2024 года за утечки действуют оборотные санкции — привязанные к выручке компании, не к фиксированной шкале. Конкретные составы и цифры разобраны в следующем разделе. Для финансиста это значит простую вещь: загрузка зарплатной ведомости с фамилиями в публичную модель это потенциальное правонарушение, а не «ну кому эти данные нужны».
Помимо КоАП есть три вещи, которые финансист подписывал лично или за которые отвечает по должности:
- Банковская тайна. Если вы работаете с выписками, остатками по счетам и условиями кредитов, это охраняемая законом тайна. Её разглашение это не штраф, а уже статья.
- NDA с контрагентами. Соглашение о неразглашении, под которым стоит ваша подпись или подпись компании. Загрузка такого документа в чужой облачный сервис это нарушение NDA само по себе, даже если утечки не случилось.
- Коммерческая тайна. Внутренний режим компании на финмодели, себестоимость, условия сделок. За её слив следует дисциплинарная и материальная ответственность вплоть до увольнения.
Провайдеры меняют политики использования данных, условия договоров и юрисдикцию хранения без индивидуального уведомления. Принцип один: данные, попавшие в чужой контур, живут по правилам этого контура, и контролировать их вы больше не можете.
При этом я не призываю отказаться от нейросетей. Призыв другой: научиться работать так, чтобы польза осталась, а риск ушёл. Для этого и нужна система уровней защиты, а не разовая перестраховка.
Ст. 13.11 КоАП, банковская тайна и NDA: что именно нарушает финансист
Загрузка реальных финансовых данных в публичную нейросеть может нарушить сразу три разных режима, и за каждый отвечает не модель, а человек и компания. Разберу простыми словами.
Ст. 13.11 КоАП. Персональные данные. ФИО сотрудника, его зарплата, ИНН физлица, телефон, адрес это персональные данные. Их обработка в России регулируется законом, а нарушение порядка обработки идёт по ст. 13.11 КоАП. В 2026 году санкции по этой статье ужесточены: штраф для юрлица до 100 тыс. руб. по базовому составу. С 2024 года за утечки персональных данных действуют оборотные штрафы: от 1% выручки, но не менее 20 млн руб. Передача персональных данных за рубеж без законных оснований это отдельный, более тяжёлый состав. Когда вы грузите зарплатную ведомость с фамилиями в ChatGPT, формально вы передаёте персональные данные иностранному оператору. Это и есть зона риска.
Банковская тайна. Сведения об операциях, счетах и вкладах охраняются законом о банковской тайне. Для финансиста это выписки, остатки, условия кредитных договоров, данные о платежах. Разглашение банковской тайны это уже не административный штраф, а потенциально уголовная ответственность для виновного лица. Поэтому такие данные не идут в публичное облако ни в каком обезличенном виде. Только уровень 3.
NDA и коммерческая тайна. NDA это соглашение о неразглашении, договор, под которым стоит подпись. Если в нём есть запрет передавать информацию третьим лицам и облачным сервисам, то загрузка документа в ChatGPT это нарушение договора сама по себе, даже без утечки. Коммерческая тайна это внутренний режим компании: себестоимость, финмодели, условия сделок. За её слив следует дисциплинарная и материальная ответственность вплоть до увольнения и иска о возмещении убытков.
Ответственность наступает за сам факт передачи, не за доказанную утечку. Загрузил зарплатную ведомость — уже нарушил, даже если данные никуда не ушли. Защита строится не на надежде «авось пронесёт», а на том, чтобы изначально не передавать то, что передавать нельзя. Именно это и делает система трёх уровней.
Что такое обезличивание данных и чем оно отличается от удаления
Обезличивание данных это замена реальных идентифицирующих признаков на маски так, чтобы по тексту нельзя было понять, о какой компании или человеке речь, но смысл для анализа сохранился. «ООО Ромашка» становится «Контрагент 1», ИНН 7701234567 становится XXXXXXXXXX, Иванов И.И. превращается в «Сотрудник А», а выручка 47,3 млн рублей округляется до «около 50 млн» или умножается на коэффициент.
На первом модуле курса я разбирала случай: финаналитик перед загрузкой реестра договоров удалил из него все суммы — «чтобы ничего лишнего». ChatGPT ответил честно: «Данных недостаточно для анализа». Полчаса работы в мусор. Псевдонимизация сохранила бы и структуру, и результат. Три понятия, которые финансист путает чаще всего:
- Удаление это когда вы просто вырезали кусок. Анализ часто ломается: модель не понимает структуру документа без названий и сумм.
- Псевдонимизация это замена на маски с сохранением ключа у вас. Это и есть рабочее обезличивание для финансиста: «Контрагент 1» можно вернуть в «ООО Ромашка» по справочнику, который остаётся только на вашем компьютере.
- Анонимизация это необратимое обезличивание без возможности восстановления. Для финанализа обычно избыточно, потому что вам потом нужно собрать отчёт обратно с настоящими названиями.
Финансисту в 95% случаев нужна именно псевдонимизация. Вы меняете данные на маски перед загрузкой, получаете анализ на масках, а потом обратной заменой возвращаете реальные названия в свой итоговый документ. Ключ-справочник в нейросеть не уходит никогда.
Главная ошибка новичка: обезличить названия, но оставить косвенные признаки. Если в тексте остались «завод по производству турбин в Рыбинске с выручкой 4 млрд», то маска «Контрагент 1» не спасает, потому что такой завод в стране один и его легко узнать. Обезличивание это про то, чтобы убрать не только прямые идентификаторы, но и уникальные сочетания признаков. Об этом я подробно говорю на уровне 1.
Какие данные финансиста нельзя грузить в ChatGPT как есть
Маскируется всё, по чему можно опознать конкретную компанию, человека или сделку. Я держу в голове короткий список того, что обезличивается всегда, и отдельный список того, что не идёт в публичное облако даже после обезличивания.
Обезличиваем всегда перед загрузкой (уровень 1 и выше):
- реальные названия компании, контрагентов, поставщиков, клиентов;
- ИНН, КПП, ОГРН, номера счетов, расчётные реквизиты;
- ФИО сотрудников, физлиц, бенефициаров;
- зарплаты, привязанные к именам;
- номера и даты конкретных договоров;
- email, телефоны, адреса;
- уникальные суммы и показатели, по которым узнаётся бизнес.
Не грузим в публичную модель даже обезличенными (только уровень 3):
- банковскую тайну: выписки, остатки, условия кредитных договоров;
- документы под жёстким NDA с прямым запретом передачи третьим лицам;
- материалы M&A, due diligence, закрытых сделок;
- данные, по которым легко восстановить компанию даже после маскирования (узкая отрасль, уникальный масштаб, привязка к региону).

Класс данных определяет уровень защиты. Управленческая отчётность это уровень 1, договоры под NDA уровень 2, банковская тайна и M&A только уровень 3.
Простое правило, которым я делюсь с финансистами: если сомневаетесь, к какому классу отнести документ, поднимайте уровень защиты, а не понижайте. Лишние пять минут на маскирование стоят дешевле штрафа и разговора с собственником о том, как данные оказались у зарубежного провайдера.
Три уровня защиты: мой фреймворк для работы с NDA-документами
За три года работы с нейросетями в финансах я свела безопасность к простой системе из трёх уровней. Не «обезличивай всё на всякий случай», а «под каждый класс данных свой уровень». Это и есть авторский фреймворк, по которому учу команды.
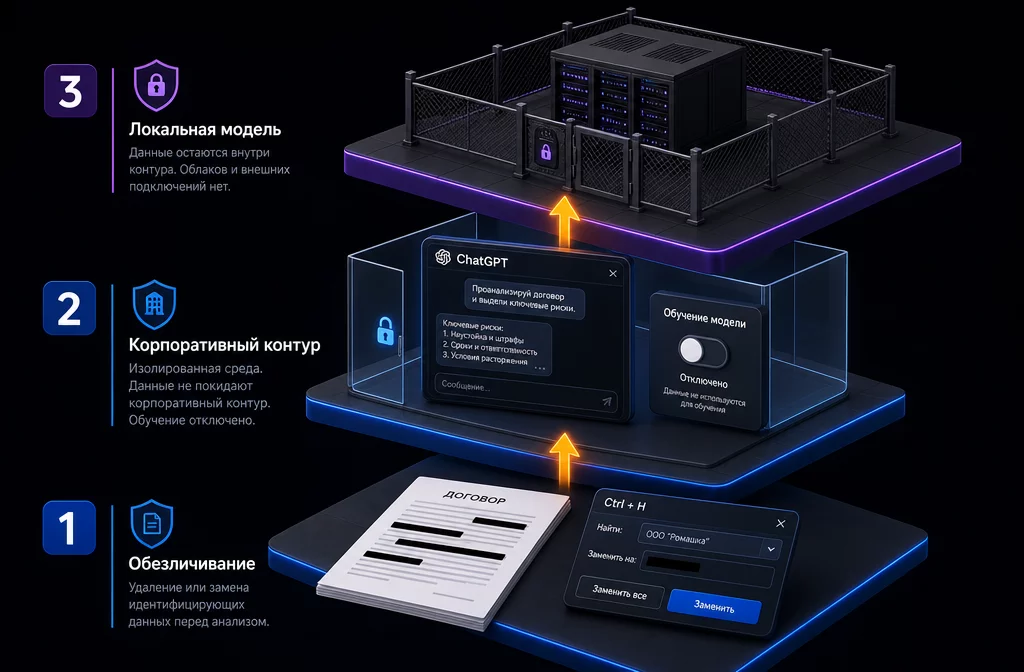
Три уровня защиты данных финансиста: обезличивание через справочник-мэппинг, корпоративный контур с Business тарифом, локальная LLM в периметре компании.
Уровни накладываются, а не заменяют друг друга: уровень 2 включает уровень 1, уровень 3 включает оба. Чем выше класс данных, тем выше уровень — не наоборот. Выбор под конкретный тип документа — в матрице ниже, в разделе «Как выбрать уровень».
Большинство задач финансиста закрывается уровнем 1. Уровень 2 нужен командам и для регулярной работы с договорами. Уровень 3 это для финдиров и компаний, где есть банковская тайна или сделки. Дальше разбираю каждый уровень по отдельности с инструментами и промптами.
Почему именно три уровня, а не один универсальный «защищённый режим». Потому что у защиты есть цена: чем выше уровень, тем больше времени и денег он требует. Обезличивание это минуты. Корпоративный контур это подписка и регламент. Локальная модель это железо и айтишник. Гонять всё через локальный контур ради проверки расчёта окупаемости дорого и медленно, а грузить банковскую тайну в публичный чат недопустимо. Система уровней это про то, чтобы платить за безопасность ровно столько, сколько требует конкретный документ, и ни рублём больше.
Уровень 1. Обезличивание: справочник-мэппинг и маскирование
Первый уровень закрывает большинство задач финансиста и стоит вам 3-5 минут на документ. Основной инструмент это справочник-мэппинг: таблица из двух колонок, реальное название и маска.
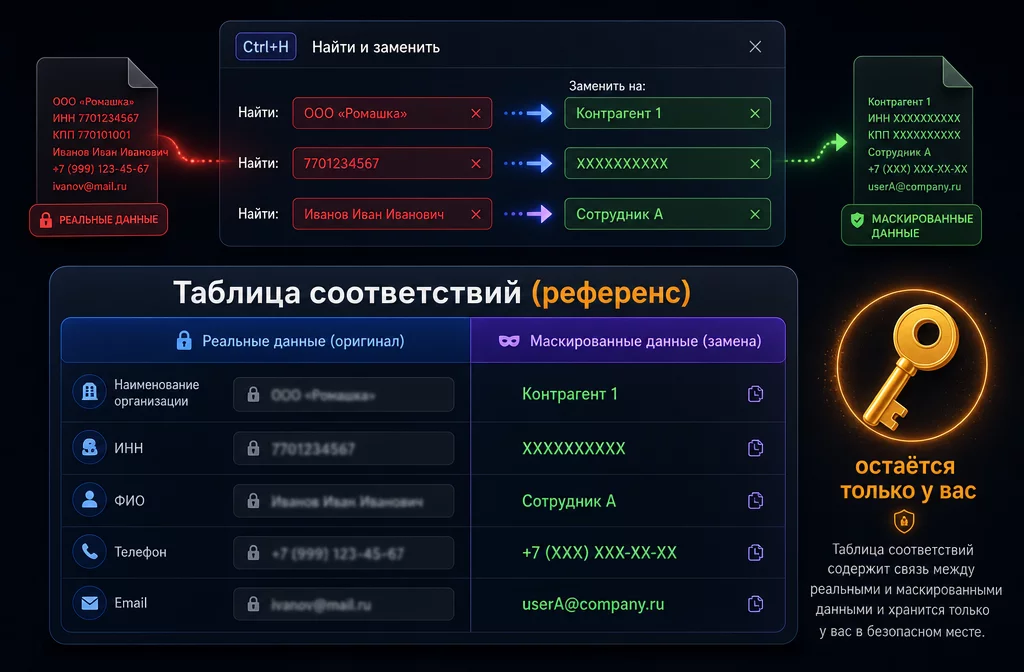
Справочник-мэппинг это таблица соответствий и ключ восстановления. Реальные названия меняются на маски через автозамену, ключ остаётся только у вас.
Как завести справочник-мэппинг
Создаёте Google Sheets или файл Excel с двумя колонками. В левую заносите реальные данные, в правую маски. Вот рабочая структура:
| Реальное | Маска |
|---|---|
| ООО «Ромашка» | Контрагент 1 |
| ООО «Василёк» | Контрагент 2 |
| 7701234567 (ИНН) | XXXXXXXXXX |
| Иванова Мария Петровна | Сотрудник А |
| Проект «Северный поток продаж» | Проект Альфа |
Один раз вносите постоянных контрагентов, реквизиты и сотрудников, дальше справочник работает на вас месяцами. Этот файл и есть ваш ключ восстановления. В нейросеть он не загружается никогда, хранится локально или в вашем закрытом облаке.
Как обезличить документ за 5 минут
Порядок действий простой и повторяемый:
- Открываете документ в Word или Google Docs.
- Через Ctrl+H (автозамена) меняете реальные названия на маски по справочнику.
- ИНН, счета и номера договоров заменяете на XXX или маски.
- ФИО убираете или меняете на «Сотрудник А, Б, В».
- Чувствительные суммы округляете или умножаете на коэффициент 0,7 или 1,3, если важна не точная цифра, а структура и динамика.
- Глазами проверяете остаточные признаки: телефоны, email, адреса, уникальные детали.
Пример: фрагмент реестра до и после обезличивания
Чтобы это перестало быть абстракцией, покажу на сквозном примере. Вот как выглядит типичная строка реестра договоров, которую финансист по привычке копирует прямо в чат:
ДО обезличивания (так грузить нельзя):
Договор поставки № 47-ПС от 12.03.2026 с ООО «Ромашка»
(ИНН 7701234567), сумма 12 480 000 ₽, ответственный
Иванова Мария Петровна, m.ivanova@romashka.ru,
отсрочка 45 дней, штраф 0,1% в день.А вот та же строка после прогона через справочник-мэппинг и автозамену. Смысл для анализа сохранён полностью, но опознать стороны по тексту уже нельзя:
ПОСЛЕ обезличивания (можно работать):
Договор поставки № Д-1 от 03.2026 с Контрагент 1
(ИНН XXXXXXXXXX), сумма ≈ 12,5 млн ₽, ответственный
Сотрудник А, отсрочка 45 дней, штраф 0,1% в день.Обратите внимание, что именно изменилось и что осталось. Изменились идентификаторы: название, ИНН, ФИО, email, точный номер и дата договора. Осталось всё, что нужно для анализа: тип договора, порядок суммы, условия отсрочки и штрафа. Модель прекрасно проверит такой договор на риски, а связать его с реальной «Ромашкой» уже невозможно. Точную сумму я округлила до «≈ 12,5 млн», потому что для проверки условий копейки не нужны, а уникальная цифра до рубля это лишний идентификатор.
Этот же принцип работает с любой строкой: меняем то, что указывает на конкретную компанию или человека, и оставляем то, что несёт экономический смысл. Справочник-мэппинг делает замену механической: один раз внесли «ООО Ромашка → Контрагент 1», и дальше автозамена меняет это во всех документах за секунды.
Три режима обезличивания под разные задачи
Не всё нужно маскировать одинаково жёстко. Я использую три режима:
| Режим | Что меняем | Когда применять |
|---|---|---|
| Лёгкий | Только названия компаний и ФИО | Внутренние черновики, типовые расчёты без чужих данных |
| Стандартный | Названия, ИНН, счета, договоры, ФИО | Большинство задач: финанализ, договоры, отчётность |
| Параноидальный | Всё перечисленное плюс суммы под коэффициент и смена отрасли на смежную | Чувствительные сделки на грани NDA |
Промпт-инструкция, которую я ставлю первым сообщением в каждой сессии с чувствительными данными:
Ты финансовый аналитик. Работай строго по данным, которые я приложил.
Все названия в тексте условные (Контрагент 1, Сотрудник А и т.п.).
Не пытайся угадать реальные компании или людей.
Не запрашивай и не додумывай недостающие реальные реквизиты.
Если данных не хватает для вывода, прямо напиши, чего не хватает.Промпт-аудитор — прогоняете через него уже замаскированный текст, чтобы найти остатки реальных данных перед загрузкой:
Проверь приложенный обезличенный текст как аудитор по защите данных.
Найди всё, по чему можно опознать реальную компанию или человека:
оставшиеся ИНН, телефоны, email, адреса, фамилии, уникальные суммы,
узнаваемые сочетания отрасль + регион + масштаб.
Выведи список найденного с пометкой, что ещё нужно замаскировать.Обезличивание Excel-файлов и скриншотов
Отдельно про то, что часто упускают. Текст обезличили, а данные всё равно утекли через два канала.
Первый канал это метаданные файла. В свойствах Excel и Word лежат автор, название организации, путь к сетевой папке вроде «сервер финотдела, папка закрытые сделки». Решение простое: после маскирования копируете нужный диапазон в новый чистый файл и грузите его, а не исходник со всей историей.
Второй канал это скриншоты. Скрин таблицы из 1С с реальными контрагентами это те же данные, только картинкой, и нейросеть их прекрасно прочитает. Скриншоты маскируем так же, как текст: либо замазываем чувствительные ячейки до съёмки, либо вообще не грузим картинку, а переносим обезличенные цифры в текст.
Третий момент это скрытые листы и формулы. В книге Excel может быть скрытый лист с реальными данными или формула, которая ссылается на закрытый источник. Перед загрузкой проверяем, что грузим только то, что видим и обезличили.
Отключение обучения на данных это обязательная часть первого уровня. В ChatGPT заходите в настройки, раздел Data Controls, и выключаете использование ваших переписок для обучения моделей. В GPT-5.5 OpenAI переработали интерфейс памяти — стало понятнее, на что именно опирается модель в ответе. Это удобно, но память и обучение это разные вещи: переключатель обучения выключаем отдельно и всегда. И помните: даже идеально обезличенный текст лучше не отдавать в обучение, потому что маски одного документа в сочетании с другими могут дать модели лишний контекст.
Уровень 2. Корпоративный контур: Business тариф и отключение обучения
Второй уровень это переход в изолированную среду провайдера, где данные юридически не уходят в обучение и хранятся отдельно. Для команды финансистов и регулярной работы с договорами под обычным NDA это правильный базовый уровень.
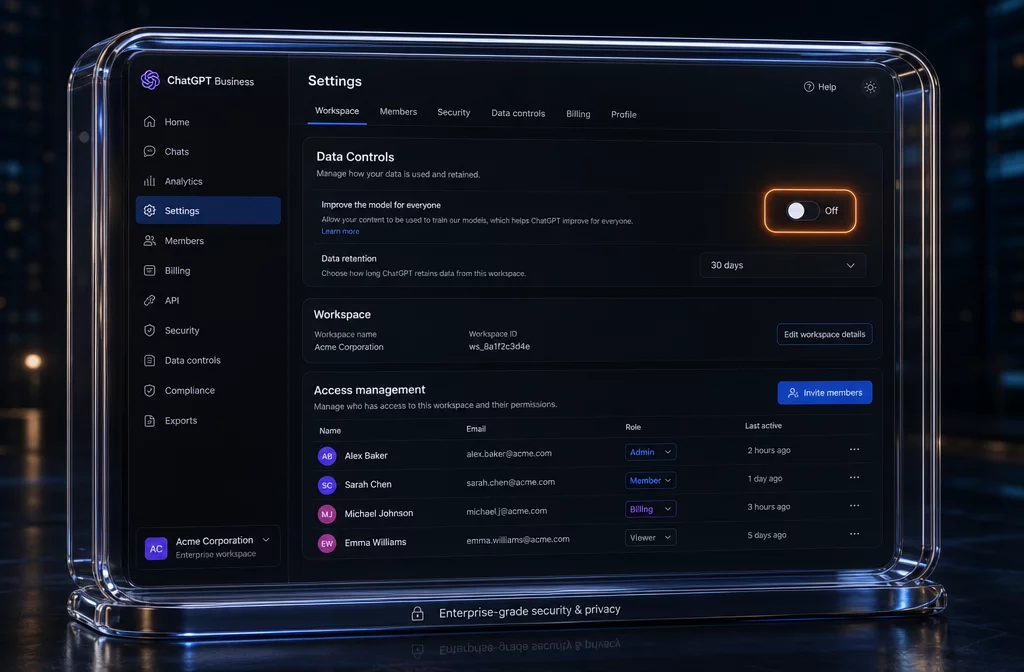
Корпоративный контур: Business и Enterprise тарифы дают изолированную среду, отключённое обучение по умолчанию и администрирование доступов.
Чем Business и Enterprise тарифы отличаются от обычного ChatGPT
В бесплатной и в личной Plus-версии вы пользователь публичного сервиса. В Business и Enterprise тарифах OpenAI берёт на себя юридические обязательства по корпоративному контуру:
- данные по умолчанию не используются для обучения моделей;
- хранение в изолированной среде с разграничением доступа;
- администрирование: вы видите, кто из команды что делает, отзываете доступы;
- журналирование и возможность настроить срок хранения переписок.
Для команды от двух-трёх финансистов это снимает большую часть рисков сразу. Тренд виден и в моей практике: из 800+ выпускников курса большинство тех, кто пришёл из компаний от пяти человек, к концу обучения переходили на командный или корпоративный контур. Главная причина не стоимость, а контроль: руководитель должен видеть, что сотрудники грузят в нейросеть и по каким правилам.
Что важно настроить на втором уровне
Корпоративный тариф это не «купил и забыл». Минимум, что настраиваю при внедрении в команде:
- Отключение обучения на уровне организации. Проверяем, что в админке выключено использование данных для тренировки.
- Срок хранения переписок. Ставим минимальный разумный, чтобы данные не копились без нужды.
- Разграничение доступа. У стажёра и у финдира разные права. Чувствительные проекты в отдельных рабочих пространствах.
- Регламент для команды. Письменное правило, что и на каком уровне можно грузить. Без регламента сотрудники всё равно понесут данные в личный бесплатный аккаунт.
API с политикой zero-retention
Если финотдел автоматизирует обработку через API (выгрузки из 1С, Google Sheets, обработка реестров), у провайдеров есть режим, при котором запросы не сохраняются и не идут в обучение. Это технический второй уровень для потоковой обработки. Важная оговорка: настройку zero-retention подтверждаем в документации и договоре с провайдером, а не на слух.
Главное, что нужно запомнить про уровень 2: он не отменяет обезличивание. Договор под NDA вы всё равно маскируете справочником-мэппингом перед загрузкой, даже на Business тарифе. Корпоративный контур снижает риск со стороны провайдера, обезличивание снижает риск со стороны самих данных. Работают вместе.
Уровень 3. Локальная LLM и российский контур для банковской тайны
Третий уровень нужен, когда данные нельзя отдавать внешнему провайдеру в принципе. Банковская тайна, M&A, жёсткий NDA с прямым запретом передачи третьим лицам. Здесь работает только одно: данные физически не покидают периметр компании.

Локальный контур: модель с открытыми весами разворачивается на сервере компании. В цепочке нет внешнего провайдера, данные не уходят наружу.
Локальная LLM на своём железе
Локальная LLM это языковая модель с открытыми весами, развёрнутая на сервере или мощном компьютере компании. Запрос обрабатывается внутри, наружу ничего не уходит. Из доступных вариантов в России это открытые модели DeepSeek, Qwen и другие модели с открытыми весами, которые можно скачать и запустить локально.
Хорошая новость: порог входа снизился. Среднюю открытую модель сегодня реально запустить на одной хорошей видеокарте для задач одного-двух финансистов, не нужен дорогой кластер. Андрей из первого кейса уложился в стоимость видеокарты плюс неделю работы айтишника. Это дешевле одного штрафа по ст. 13.11 КоАП.
Честная оговорка: для команды это всё равно ИТ-проект, а не кнопка. Нужны железо, человек, который развернёт и обновит модель, и понимание, что локальная модель обычно слабее свежего флагмана вроде GPT-5.5. Зато данные не уходят никуда. Для банковской тайны это не компромисс, а единственный допустимый вариант.
Российский контур и on-prem решения
Альтернатива своему железу это российские решения, которые работают в защищённом контуре: YandexGPT и GigaChat в корпоративных конфигурациях, а также on-prem развёртывание, когда модель ставится на инфраструктуру компании под её контролем. Для данных, которые по закону должны оставаться в российской юрисдикции, это рабочий путь.
Почему зарубежные серверы это отдельный риск
Юрисдикция данных это не абстракция. Данные на серверах любой страны живут по правилам этой страны, и эти правила меняются без вашего участия: сегодня у провайдера одна политика хранения, завтра другая, а ваши данные уже там. Поэтому банковскую тайну и материалы сделок я держу там, где провайдера в цепочке нет вообще.
Вот как я объясняю выбор уровня 3 финдирам: вопрос не в том, доверяете ли вы конкретному провайдеру сегодня. Вопрос в том, готовы ли вы потерять контроль над данными, если правила провайдера или его страны изменятся завтра. Для банковской тайны ответ всегда нет, поэтому только локальный контур.
Как выбрать уровень защиты под конкретный документ
Смотрите на самый чувствительный элемент в документе и выбирайте уровень по нему. Один реальный номер счёта поднимает весь документ на уровень, который требуется для банковской тайны.
Моя матрица выбора, по которой решаю за тридцать секунд:
| Документ | Что в нём чувствительного | Уровень |
|---|---|---|
| Управленческий ОДДС, P&L без имён | Структура, динамика | 1 (обезличивание) |
| Расчёт окупаемости проекта | Суммы, контрагенты | 1 (обезличивание) |
| Договор поставки под NDA | Стороны, условия, суммы | 2 (корпоративный контур) + обезличивание |
| Реестр контрагентов с ИНН | Персональные и налоговые данные | 2 + обезличивание |
| Зарплатная ведомость с ФИО | Персональные данные | 2 минимум, лучше 3 |
| Банковские выписки, остатки | Банковская тайна | 3 (локальный контур) |
| Материалы M&A, due diligence | Закрытая сделка | 3 (локальный контур) |
Три вопроса, которые задаю себе перед загрузкой любого документа:
- Есть ли здесь персональные данные физлиц? Если да, минимум уровень 2 и обязательное обезличивание ФИО.
- Подпадает ли это под NDA или банковскую тайну? Если NDA, уровень 2. Если банковская тайна, уровень 3.
- Можно ли узнать компанию по косвенным признакам после маскирования? Если да, либо маскируем глубже, либо поднимаем уровень.
Если на все три вопроса ответ спокойный, работаете на уровне 1 и экономите время. Если хоть один тревожный, поднимаете уровень. Это занимает полминуты и встраивается в привычку за неделю.
Обезличивание в разных нейросетях: ChatGPT, Claude, Gemini, DeepSeek
Для безопасности важнее тариф и настройки, чем бренд модели, но различия между сервисами есть, и финансисту их полезно знать. Свожу в таблицу то, что проверяю при настройке каждого инструмента.
| Сервис | Отключение обучения | Корпоративный контур (уровень 2) | Локально (уровень 3) | Нюанс для финансиста |
|---|---|---|---|---|
| ChatGPT (GPT-5.5) | Data Controls, выключаем вручную | Business / Enterprise | Нет | Универсал, мощный контур для команды |
| Claude (Sonnet 4.6) | Обучение на данных по умолчанию выключено | Team / Enterprise | Нет | Аккуратен с длинными договорами под NDA |
| Gemini (2.5) | Настройка Activity | Workspace | Нет | Силён в больших таблицах, удобен в экосистеме Google |
| DeepSeek (V3.2) | Веб-версия, серверы в Китае | Слабее по гарантиям | Да, открытые веса | Единственный из списка разворачивается локально |
ChatGPT. Самый зрелый корпоративный контур для команды. Отключение обучения в Data Controls включаем сразу. Для NDA-договоров рабочая связка это Business тариф плюс обезличивание.
Claude. Обучение на данных пользователей по умолчанию отключено, и это приятная гарантия из коробки. Claude аккуратнее держит контекст длинных документов, поэтому на обезличенные договоры я часто беру именно его. Детали в разборе Claude для финансиста.
Gemini. Удобен, если финотдел живёт в Google Workspace и таблицах. Безопасность настраивается в Activity и на уровне Workspace. Подробнее в статье Gemini для финансиста.
DeepSeek. Единственный из четвёрки, который можно развернуть локально благодаря открытым весам. Но у веб-версии серверы в Китае, а значит, чужая юрисдикция. Поэтому в публичной веб-версии DeepSeek обезличивание это жёсткое правило входа, а для банковской тайны рассматриваем только локальное развёртывание. Подробный разбор в статье DeepSeek для финансиста без VPN.
Бренд модели влияет на качество ответа, но не на безопасность. Безопасность данных дают три вещи независимо от бренда: обезличивание, отключение обучения и правильный контур под класс данных. «Какая модель умнее» и «какая модель безопаснее» — разные вопросы с разными ответами.
10 готовых промптов для безопасной работы с финансовыми данными
Ниже промпты, которые я использую с обезличенными данными. Все они написаны так, чтобы модель работала строго по приложенному и не пыталась додумать реальные реквизиты. Подставляйте свои маски из справочника.
1. Системная инструкция против запоминания реальных данных. Ставьте первым сообщением сессии.
Ты финансовый аналитик с опытом в управленческом учёте.
Все названия и цифры в нашем диалоге условные и обезличенные.
Не пытайся определить реальные компании, людей или сделки.
Не запрашивай настоящие ИНН, счета, ФИО.
Работай только с тем, что я приложил. Чего не хватает, спроси прямо.2. Финанализ обезличенного ОДДС.
Проанализируй приложенный ОДДС за квартал (данные обезличены).
Найди аномалии и резкие отклонения по статьям, опиши динамику
ключевых потоков, сформулируй 5 вопросов, которые финдир задаст
к этим цифрам. Считай в коде, покажи расчёты. Не додумывай статьи,
которых нет в данных.3. Проверка обезличенного договора на риски.
Ты финансист, проверяющий договор (стороны обезличены: Контрагент 1
и Контрагент 2). Найди финансовые риски: условия оплаты, штрафы,
авансы, валютные оговорки, скрытые комиссии. Дай список рисков
с пометкой степени. Юридическую экспертизу не подменяй, отметь,
что уйдёт юристу.4. Сверка двух обезличенных таблиц.
Сверь две приложенные таблицы (данные обезличены). Найди расхождения
по суммам и позициям построчно. Выведи таблицу: позиция, значение 1,
значение 2, расхождение. Считай в коде. Не выравнивай цифры сам,
показывай разницу как есть.5. Финмодель окупаемости на условных данных.
Собери модель окупаемости проекта по обезличенным вводным:
инвестиции, выручка по периодам, расходы, ставка дисконтирования.
Посчитай срок окупаемости, NPV, IRR. Считай в коде, покажи формулы
и таблицу по периодам. Отметь, какие допущения ты принял.6. Пояснительная записка к отчётности.
Напиши пояснительную записку к приложенному обезличенному отчёту
для собственника. Деловой русский, без вводных абзацев, сразу к цифрам
и причинам, до 400 слов. Объясни главные изменения и причины. Названия оставь условными, я подставлю
реальные сам.7. Каркас ответа на требование ИФНС.
Составь каркас ответа на требование налоговой по приложенным
обезличенным данным. Структура: вводная, суть, обоснование, приложения.
Формулировки нейтральные и корректные. Конкретные нормы НК и реквизиты
я проверю и подставлю сам, не выдумывай номера писем и статей.8. Аудитор обезличивания (самопроверка текста).
Проверь приложенный текст как специалист по защите данных.
Найди всё, по чему можно опознать реальную компанию или человека:
оставшиеся ИНН, телефоны, email, адреса, фамилии, уникальные суммы,
узнаваемые связки отрасль + регион + масштаб. Выведи список того,
что ещё нужно замаскировать.9. Генерация структуры справочника-мэппинга.
Помоги составить структуру справочника-мэппинга для обезличивания
финансовых документов. Перечисли категории данных, которые финансист
должен маскировать, и предложи формат масок для каждой категории.
Реальные данные не нужны, нужна только схема.10. Бюджет и план-факт на условных цифрах.
Сделай план-факт анализ по приложенным обезличенным данным бюджета.
Найди статьи с отклонением больше 10%, объясни вероятные причины,
предложи 3 управленческих вывода. Считай в коде. Не достраивай
статьи, которых нет.Складывайте рабочие промпты в отдельную папку или заметку. Через месяц у вас будет личная библиотека, и обезличенная работа станет такой же быстрой, как обычная.
Кейсы: как финансисты внедрили обезличивание на практике
Покажу три истории участников курса с цифрами. Имена изменены по их просьбе, что само по себе пример обезличивания.
Кейс 1. Финдир производства: банковская тайна и уровень 3
Андрей, финансовый директор производственной компании, 12 лет опыта, кредитный портфель в трёх банках.
Точка А. Грузил в ChatGPT всё подряд, включая выписки и условия кредитов, чтобы быстро считать ковенанты и долговую нагрузку. Экономил время, но при проверке службой безопасности выяснилось, что банковская тайна и условия кредитных договоров уходили в зарубежный сервис. Риск нарушения договоров с банками и ст. 13.11 КоАП.
Что сделали. Развели работу по уровням. Управленческую отчётность оставили на уровне 1 с обезличиванием. Для аналитики команды подключили корпоративный контур (уровень 2). Под банковскую тайну и расчёт ковенант развернули локальную модель на сервере компании (уровень 3): данные перестали покидать периметр.
Точка Б. Скорость работы не упала, банковская тайна больше не уходит наружу. Служба безопасности согласовала использование AI. Андрей сохранил примерно 10 часов в неделю: большая часть — расчёты ковенант и долговой нагрузки, которые раньше занимали полный рабочий день. Без риска для компании и без личной ответственности за слив. «Локальная модель обошлась в стоимость одной видеокарты и недели работы айтишника. Дешевле любого штрафа».
Кейс 2. Главбух: справочник-мэппинг и уровень 1
Светлана, главбух торговой компании, 9 лет в профессии, около 60 постоянных контрагентов.
Точка А. Использовала ChatGPT для проверки договоров и реестров, грузила с реальными названиями и ИНН. На вопрос об обезличивании отвечала, что времени нет вручную всё переписывать.
Что сделали. Завели справочник-мэппинг на 60 контрагентов один раз, настроили автозамену через Ctrl+H, включили отключение обучения в настройках. Обезличивание одного документа упало с 15 минут до 3-4. Договоры под жёстким NDA вывели из публичной модели полностью.
Точка Б. Риск утечки персональных и налоговых данных снят, скорость работы выросла, потому что справочник заодно ускорил подстановку названий. Светлана экономит 4–5 часов в неделю на проверке договоров и сверках с контрагентами — ровно там, где раньше был риск. «Без страха, что данные клиентов всплывут где-то на чужих серверах». Три минуты на автозамену оказались самой дешёвой страховкой.
Кейс 3. Финаналитик в группе компаний: корпоративный контур
Дмитрий, финансовый аналитик группы компаний, 7 лет опыта, команда из четырёх человек.
Точка А. Каждый в команде пользовался личным бесплатным ChatGPT, кто-то с обезличиванием, кто-то без. Единого правила не было, контроля тоже. Данные группы расходились по личным аккаунтам сотрудников.
Что сделали. Перевели команду на корпоративный Business тариф (уровень 2), отключили обучение на уровне организации, написали регламент: что и на каком уровне грузим. Чувствительные проекты развели по отдельным рабочим пространствам. Обезличивание оставили обязательным даже внутри контура.
Точка Б. Данные группы перестали растекаться по личным аккаунтам, у руководителя появился контроль доступов. Главное изменение по процессу: ежемесячные консолидации и план-факт по нескольким юрлицам раньше каждый аналитик строил в своём личном аккаунте — Дмитрий как координатор потом собирал всё вручную в итоговый файл. После внедрения единого контура, шаблонов и стандартных промптов сводная работа закрывается за один сеанс вместо дня переклейки. По аналитическим группам такого размера в моей практике экономия на координаторских задачах — 3-4 часа в неделю, на линейных задачах аналитика — 2-3 часа. Business-тариф на четверых окупился примерно за три недели только на этой экономии. «Раньше каждый отвечал сам за себя и никто ни за что. Теперь есть контур и правила».
Типичные ошибки обезличивания, которые всё равно сливают данные
Обезличивание защищает только если сделано правильно. Перечисляю промахи, из-за которых маскирование превращается в иллюзию безопасности.
1. Маскируют название, но забывают косвенные признаки. «Контрагент 1» с выручкой 4 млрд в узкой отрасли и в конкретном городе опознаётся за минуту. Уникальные сочетания признаков обезличиваем тоже.
2. Грузят ключ-справочник вместе с документом. Справочник-мэппинг это ключ восстановления, он не идёт в нейросеть никогда. Иначе вы сами свели маски к реальным данным.
3. Оставляют данные в метаданных файла. Загружаете Excel, а в свойствах файла автор, название компании, путь к сетевой папке. Чистите метаданные или копируете данные в новый чистый файл.
4. Обезличивают текст, но не картинки. Скриншот таблицы из 1С с реальными названиями это те же данные. Картинки маскируем так же, как текст.
5. Понижают уровень ради скорости. «Сегодня некогда разворачивать локальную модель, загружу выписку в обычный чат разок». Этот «разок» и есть нарушение. Уровень определяется данными, а не настроением.
6. Считают, что бесплатный тариф безопаснее, потому что «там никто не смотрит». Наоборот, в бесплатной версии меньше всего гарантий по данным. Уровень защиты дают тариф и обезличивание, а не надежда.
7. Не настроили отключение обучения. Даже идеально обезличенный текст лучше не отдавать в обучение. Тумблер в Data Controls выключаем один раз и навсегда.
Все семь ошибок объединяет одно: человек сделал вид, что защитил данные, но защита дырявая. Обезличивание это не галочка, а проверяемый результат. Поэтому в моей системе есть отдельный шаг самопроверки текста перед загрузкой.
Будущее: регулирование персональных данных и AI в 2026-2027
Три тренда на горизонте 6-12 месяцев, которые меняют цену вопроса для финансиста.
Первое. Штрафы за данные растут, а не снижаются. С 2024–2025 года за утечки персональных данных действуют оборотные штрафы — привязанные к выручке компании, не к фиксированной шкале КоАП. Составы и цифры разобраны выше, в правовом разделе. Финансист, принимающий решение о Business-тарифе, должен держать в голове эту асимметрию: штраф за утечку несравнимо дороже любой подписки. Финансисты, выстроившие систему защиты данных сейчас, входят в этот период подготовленными. Те, кто грузит сырые данные в публичный чат, рискуют сильнее с каждым кварталом.
Второе. Локальные модели становятся доступнее. Модели в 7–14 млрд параметров, которые закрывают большинство задач финансиста — проверку договоров, финанализ, сводные таблицы, — сегодня запускаются на видеокарте за 150–200 тысяч рублей. Год назад аналогичная задача требовала сервер за 1–2 млн рублей или дорогое облако. DeepSeek V3.2 с открытыми весами уже доступен для локального развёртывания, и порог входа продолжает снижаться. Банковская тайна и AI перестают быть взаимоисключающими.
Третье. AI-агенты повышают цену слитых данных. Агент это модель, которая выполняет цепочку действий сама. Microsoft 365 Copilot с режимом агентов доступен корпоративным пользователям как отдельная надстройка к подписке M365: агент может собрать данные из почты, таблицы и CRM в одном сеансе без вашего участия. Если на входе необезличенные данные, за один проход они могут оказаться в нескольких сервисах сразу. Чем автономнее инструмент, тем важнее, чтобы на входе были уже защищённые данные.
Вывод простой. Обезличивание и уровни защиты не устаревают от того, что модели умнеют. Наоборот, цена ошибки растёт вместе с возможностями инструментов. Финансист, который выстроил систему защиты данных сейчас, через год получает фору перед теми, кто всё ещё грузит выписки в публичный чат «по-быстрому».
FAQ: частые вопросы про обезличивание данных в ChatGPT
Обязательно ли обезличивать данные, если включено отключение обучения? Да. Отключение обучения запрещает провайдеру тренироваться на ваших переписках, но не делает данные анонимными и не выводит их из облака. Это две разные линии защиты. Обезличивание убирает риск со стороны самих данных, отключение обучения со стороны провайдера. Работают только вместе.
Можно ли грузить договор под NDA в ChatGPT, если обезличить стороны? Зависит от NDA. Если соглашение прямо запрещает передачу третьим лицам и облачным сервисам, то даже обезличенный документ лучше держать на уровне 2 (корпоративный контур) или уровне 3. Обезличивание снижает риск восстановления, но факт передачи документа провайдеру при жёстком NDA уже может быть нарушением.
Какой штраф грозит за загрузку персональных данных в нейросеть? Ответственность идёт по ст. 13.11 КоАП — три разных состава с разной тяжестью: нарушение порядка обработки персональных данных, трансграничная передача без оснований и оборотные санкции за утечки. Конкретные цифры по каждому составу разобраны в разделе «Ст. 13.11 КоАП, банковская тайна и NDA» выше. Отвечает компания и должностное лицо, а не нейросеть.
Достаточно ли округлить суммы, чтобы обезличить отчёт? Нет. Суммы это лишь один признак. Нужно убрать названия, ИНН, ФИО, реквизиты и уникальные сочетания признаков, по которым узнаётся компания. Округление сумм это часть параноидального режима, а не самостоятельная защита.
Что безопаснее для финансовых данных: ChatGPT, Claude или локальная модель? Для обычных задач разница в тарифе и настройках, а не в бренде. На уровне 2 корпоративные контуры есть и у ChatGPT, и у Claude. Для банковской тайны безопаснее всего локальная модель в периметре компании, потому что внешнего провайдера в цепочке нет вообще. Подробнее про инструменты в моих разборах ChatGPT для финансиста и Claude для финансиста.
Нужен ли финансисту-одиночке Business тариф? Не всегда. Если вы в найме и работаете с обычной отчётностью, хватает уровня 1: обезличивание плюс отключение обучения на личном тарифе. Business нужен команде и для регулярной работы с договорами под NDA. Банковскую тайну ни тот, ни другой тариф не закрывают, для неё уровень 3.
Как обезличить данные в Excel-файле перед загрузкой? Заводите справочник-мэппинг, через Найти и заменить (Ctrl+H) меняете названия на маски прямо в файле, копируете нужный диапазон в новый чистый файл, чтобы не тащить метаданные и скрытые листы. Подробно про работу с таблицами в статье нейросеть для Excel финансисту.
С чего начать, если раньше грузил данные без обезличивания? С двух действий за один вечер. Первое: включите отключение обучения в настройках ChatGPT. Второе: заведите справочник-мэппинг на ваших постоянных контрагентов. Дальше каждый документ проходит через автозамену за 3-5 минут. Этого хватает, чтобы закрыть уровень 1 и убрать большую часть риска уже завтра.
Чек-лист обезличивания перед загрузкой в ChatGPT
Пройдите по восьми пунктам перед каждой загрузкой чувствительного документа. Это занимает минуту и убирает основную часть риска.
- Определите уровень. Управленческая отчётность это уровень 1, NDA это уровень 2, банковская тайна это уровень 3. Не понижайте.
- Замените названия. Контрагенты, поставщики, клиенты на «Контрагент 1, 2, 3» через Ctrl+H по справочнику.
- Замаскируйте реквизиты. ИНН, КПП, счета, номера и даты договоров на XXX или маски.
- Уберите ФИО. Сотрудники и физлица на «Сотрудник А, Б, В». Зарплаты отвяжите от имён.
- Обработайте суммы. Чувствительные цифры округлите или умножьте на коэффициент, если важна структура, а не точность.
- Проверьте косвенные признаки. Отрасль, регион, масштаб, уникальные детали, по которым узнаётся компания.
- Почистите файл. Метаданные, свойства документа, скрытые листы, скриншоты с реальными данными.
- Включите контур. Отключение обучения в настройках, для команды корпоративный тариф, для банковской тайны локальная модель.
Восемь галочек, и документ готов к загрузке. Распечатайте список или держите в заметке первые две недели, потом он работает на автомате.
Финальный CTA: на курс «AI-навыки финансиста»
Эта статья даёт систему трёх уровней, 10 промптов и чек-лист обезличивания. Но безопасная работа финансиста с AI это не один приём, а выстроенный процесс: связка моделей под задачи (ChatGPT, Claude, Gemini, DeepSeek, YandexGPT), свои промпты под отрасль, правильное обезличивание, корпоративный контур, локальные решения под банковскую тайну, связка с 1С и Google Sheets.
На курсе «AI-навыки финансиста» онлайн-школы «Финансовый директор | Мастер CFO» эта система собрана целиком: 10 модулей, 800+ выпускников, диплом установленного образца с лицензией, налоговый вычет 13%. Я веду курс лично, разбираю реальные кейсы участников на эфирах, отдельный модуль посвящён безопасности данных и работе под NDA. Вы перестаёте бояться за данные и начинаете экономить часы системно.
Записаться на курс «AI-навыки финансиста»
Об авторе
Натали Васильева. Продюсер онлайн-школы «Финансовый директор | Мастер CFO». С нейросетями в работе финансиста с февраля 2023 года. Через мой курс «AI-навыки финансиста» прошли 800+ финансистов, главбухов и финдиров. Веду Telegram-канал @findir_pro (45 000+ подписчиков), MAX-канал «Финансовый директор» (5 000+) и YouTube-канал онлайн-школы. Личный набор: ChatGPT Plus, Claude Pro, Gemini Advanced, DeepSeek, YandexGPT, GigaChat.