AI для финансиста
ChatGPT o3 и o4-mini для финансиста: reasoning-модели которые думают как аналитик McKinsey
В апреле 2025 года OpenAI выпустил o3 и o4-mini — модели, которые изменили правила работы с финансовыми задачами. Не потому что стали «умнее» в рекламном смысле, а потому что впервые начали думать перед ответом: строить цепочку рассуждений, находить собственные ошибки, честно говорить, где логика не сходится. Это было именно то, чего финансист ждал от нейросети годами. Я Натали Васильева, эксперт по нейросетям и продюсер онлайн-школы «Финансовый директор | Мастер CFO». В этой статье разбираю, что o3 и o4-mini принесли в финансовую практику, как эти возможности работают в GPT-5.5 сегодня, и даю 8 промптов, которые вы заберёте прямо сейчас.
Что такое reasoning-модели и почему это не просто «умный ChatGPT»
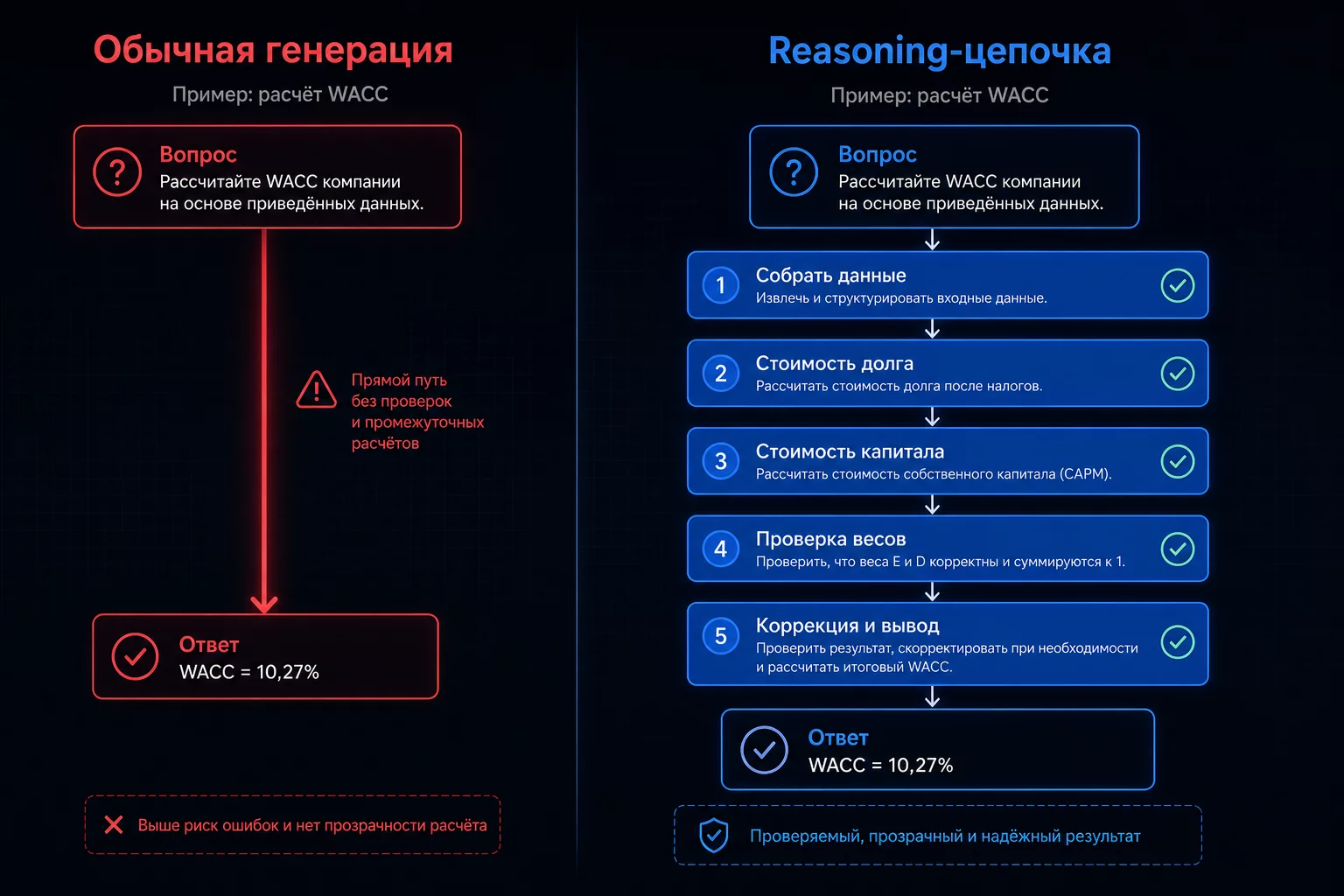
Обычная генерация: ответ сразу. Reasoning: внутренняя цепочка шагов, проверка логики, только потом ответ.
Reasoning-модель думает перед тем, как ответить. Внутри — невидимая вам цепочка шагов: модель раскладывает задачу, проверяет каждый шаг, находит противоречия, корректирует и только потом формулирует финальный ответ.
Обычный ChatGPT работает иначе. Он генерирует ответ слово за словом, не имея возможности «отмотать назад» и исправить ошибку в середине цепочки. На коротких задачах разницы нет. На многошаговых — принципиальная.
Представьте, что вы строите расчёт окупаемости нового цеха: 28 шагов, три сценария, переменная ставка дисконтирования. На шаге 17 нужно применить налоговый щит на проценты по кредиту. Обычная модель пропускает этот шаг или применяет его к неправильной базе — и выдаёт красивый финансовый анализ с ошибкой внутри. Reasoning-модель на этом шаге останавливается: «Стоп, база для расчёта налогового щита здесь — проценты, а не тело долга. Пересчитываю.» Вы получаете результат с объяснением.
Что открыл o3 для финансиста:
- Самостоятельная проверка расчётов перед выдачей ответа
- Честное «не уверен» там, где данных не хватает, вместо придуманной цифры
- Видимая логика: можно прочитать ход рассуждений и найти спорный шаг
- Устойчивость на длинных задачах — модель не «теряет нить» на шаге 25 из 28
Как появились o3 и o4-mini: контекст для финансиста
OpenAI запустил o3 и o4-mini в апреле 2025 года как ответ на запрос рынка: инженеры и аналитики требовали не «более умного текста», а надёжных многошаговых рассуждений. До этого был o1 (конец 2024-го), но он работал медленно и стоил дорого. O3 и o4-mini нашли баланс между глубиной мышления и практической скоростью.
В финансовом сообществе принятие было быстрым. Через три месяца после выхода в наших чатах в Telegram-канале @findir_pro (45 000 подписчиков) пошли кейсы: финдиры писали, что впервые доверяют нейросети проверить многошаговый расчёт. Не написать его с нуля — именно проверить. Это другой уровень доверия.
Чем o4-mini отличался от o3:
| Параметр | o3 | o4-mini |
|---|---|---|
| Глубина рассуждений | максимальная, медленнее | на 90-95% от o3, втрое быстрее |
| Цена токена | выше | существенно ниже |
| Оптимальные задачи | инвестиционный анализ, сложные финмодели | план-факт, сценарный анализ, верификация расчётов |
| Время ожидания | 30-60 секунд на сложной задаче | 10-20 секунд |
| Мультимодальность | текст + данные | текст + таблицы + документы |
Для большинства CFO-задач o4-mini был лучшим выбором: скорость, цена и качество на структурированных финансовых данных. O3 я рекомендовала для самых сложных инвестиционных разборов, где важна была максимальная глубина проверки.
К 2026 году OpenAI интегрировал лучшее из обеих моделей в GPT-5.5. Отдельного переключателя больше нет — reasoning-логика стала базовым слоем. Но понимать, как эти модели работают, по-прежнему важно: именно это знание определяет, получите ли вы от GPT-5.5 анализ уровня McKinsey или очередную красивую воду.
Где reasoning-мышление обходит обычный ChatGPT в финансовой работе

Пять зон финансовой работы, где reasoning меняет исход: расчёты, анализ, проверка логики.
Обычный ChatGPT отлично справляется с составлением писем, переводами, конспектами совещаний, перефразированием. Reasoning-подход нужен там, где есть цепочка шагов с зависимостями и где ошибка в середине ломает весь результат.
Пять зон, где reasoning меняет исход:
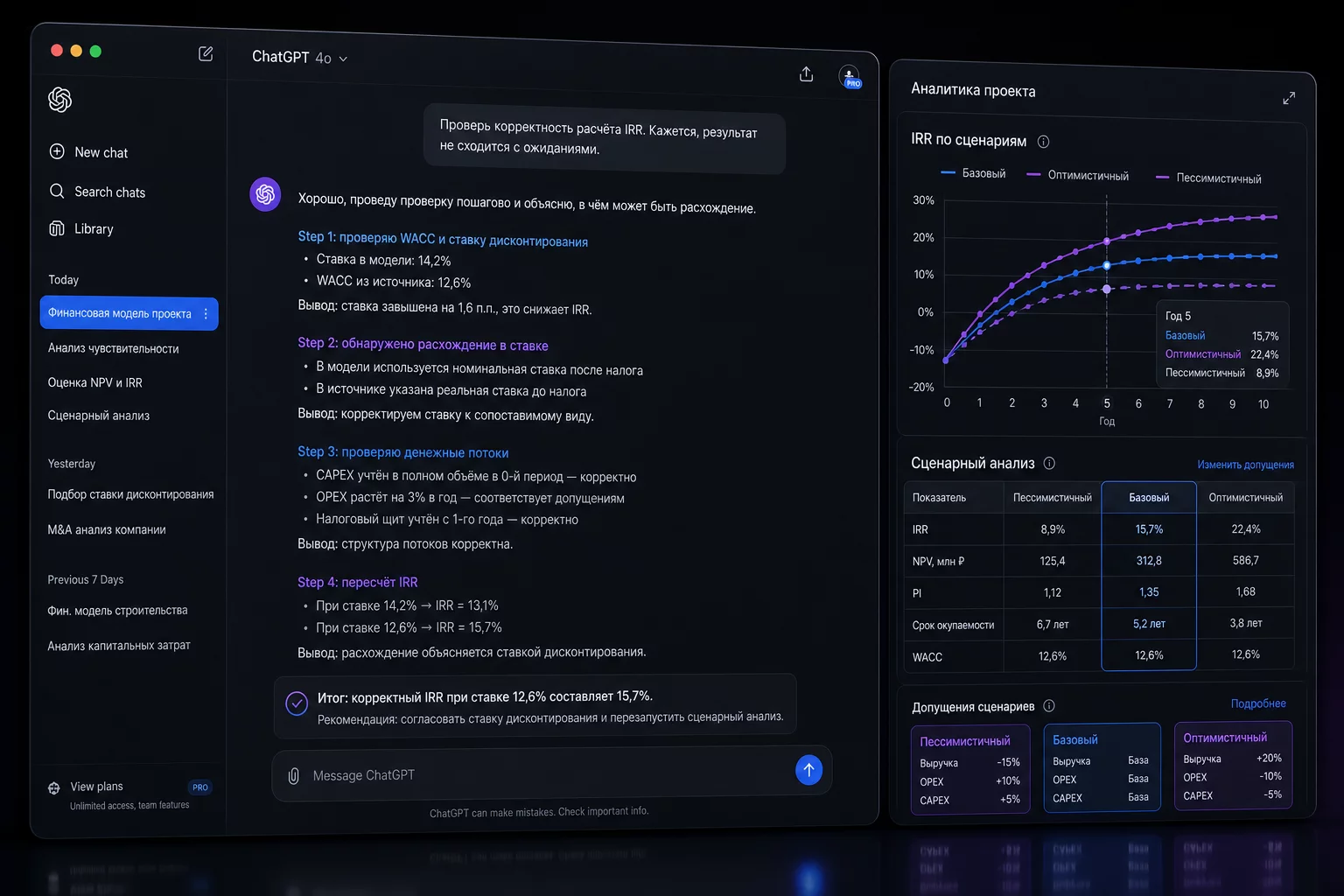
1. Проверка финансовых моделей. Вы строите финмодель в Excel, нейросеть проверяет методологию. Обычный ChatGPT читает и подтверждает: «Всё выглядит корректно». Reasoning-модель строит параллельную цепочку и пишет: «На шаге расчёта WACC вы используете рыночную ставку долга 8,5%, но в разделе допущений указано 11%. Какое значение применять?» Финансист, который строил эту модель три дня, находит ошибку за две минуты.
2. Сценарный анализ CFO. Три сценария (базовый, оптимистичный, стрессовый) с разными допущениями по выручке, инфляции и ставке кредита. Обычная модель посчитает каждый сценарий последовательно. Reasoning проверяет внутреннюю совместимость: «В стрессовом сценарии выручка снижается на 30%, но вы сохраняете операционные затраты на уровне базового. Это намеренно? Или нужно пересчитать с учётом переменной части?»
3. Анализ инвестиционного меморандума. Документ на 60 страниц, прогнозы выручки, структура сделки, мультипликаторы. Обычная модель читает и резюмирует. Reasoning-модель ловит, что мультипликатор EV/EBITDA в меморандуме рассчитан на скорректированном EBITDA без раскрытия корректировок, а прогноз роста выручки в два раза превышает среднеотраслевой без обоснования.
4. Верификация сложных расчётов. ОДДС, план-факт, анализ оборачиваемости по 15 товарным группам. Reasoning-модель не просто выдаёт таблицу — она проверяет балансовые соотношения, находит строки, где сумма колонок не сходится, и указывает на возможные двойные учёты.
5. Договор с нестандартной структурой. Инвестиционный договор с плавающими условиями, конвертируемый займ, оферта с пороговыми показателями. Reasoning-модель строит карту условных обязательств: «Если выручка по итогам 2026 года ниже 150 млн рублей, кредитор имеет право требовать досрочного погашения согласно п. 4.3. При этом п. 7.1 исключает это право на первые 18 месяцев. Есть противоречие, которое нужно уточнить.»
Метод STAR-F: как составить промпт для reasoning-задачи
Обычный промпт для reasoning-задачи не работает так, как мог бы. «Проверь мою финмодель» — и модель сделает поверхностный разбор. «Напиши анализ этого инвестмеморандума» — получите резюме без критики.
Метод STAR-F я разработала как структуру, которая активирует reasoning-мышление в полную силу:
- S (Situation) — ситуация и контекст: кто вы, какая задача, какие данные
- T (Task) — конкретная задача с критериями успеха
- A (Action) — как именно анализировать, какие шаги пройти
- R (Reasoning) — явная просьба показать логику и проверить шаги
- F (Format) — в каком виде нужен результат
Без R-блока модель не переходит в режим глубокого рассуждения. Это самый важный элемент.
Шаблон промпта STAR-F:
Ты — финансовый аналитик с опытом верификации инвестиционных расчётов.
[S] Ситуация: я CFO производственной компании, выручка 800 млн рублей, готовлю проверку финмодели для сделки M&A.
[T] Задача: проверить корректность расчёта WACC и DCF в приложенной модели. Критерий: найти все шаги, где методология расходится со стандартом или с нашими допущениями.
[A] Действие: сначала восстанови допущения из текста, потом пройди по формуле WACC шаг за шагом, потом проверь DCF на соответствие WACC.
[R] Рассуждение: объясни каждый шаг своих рассуждений. Если что-то неоднозначно — напиши об этом явно, не угадывай. Если уверен в ошибке — укажи конкретный шаг и почему он неверный.
[F] Формат: сначала список найденных проблем с уровнем критичности (высокий/средний/низкий), потом подробное объяснение каждой.Этот шаблон я использую со своими ученицами на курсе «AI-навыки финансиста» с первого дня. На практике 80% сложных аналитических задач закрываются через него или его адаптацию.
8 готовых промптов для финансиста: reasoning-уровень

8 промптов с reasoning-логикой для CFO, финдира и главбуха. Копируйте и адаптируйте под свои данные.
Промпты написаны для GPT-5.5 (ChatGPT Plus, chatgpt.com). Работают с любой reasoning-моделью. Подставляйте свои данные вместо [скобок].
Промпт 1. Проверка финансовой модели на методологические ошибки
Ты — старший финансовый аналитик с опытом верификации DCF-моделей для M&A.
Ситуация: я готовлю инвестиционное решение по [название проекта], финмодель в приложении.
Задача: найди все методологические ошибки и допущения, которые не обоснованы.
Анализируй пошагово:
1. Сначала восстанови ключевые допущения модели из текста.
2. Проверь WACC: ставка долга, ставка собственного капитала, структура капитала, формула.
3. Проверь DCF: терминальная стоимость, горизонт, логика денежных потоков.
4. Найди расхождения между допущениями в разных частях документа.
Показывай логику каждого шага. Если что-то неоднозначно — пиши «неоднозначно» и объясни почему. Не придумывай цифры.
Формат: список проблем (уровень критичности: высокий/средний/низкий) + подробное объяснение.Промпт 2. Анализ инвестиционного меморандума
Ты — финансовый директор, который оценивает сделку для совета директоров.
Задача: проанализировать инвестиционный меморандум [компания/проект] и подготовить независимое заключение.
Пройди три слоя анализа:
1. Финансовый: прогнозы выручки, EBITDA, денежный поток — реалистичны ли допущения?
2. Методологический: мультипликаторы, сравнение с аналогами, логика оценки.
3. Риски: что намеренно замолчано, где данные неполные, какие вопросы нужно задать продавцу.
Покажи логику рассуждений. Для каждого тезиса укажи: на каком конкретном месте в документе основан вывод.
Формат: структурированный отчёт с разделами + финальный вердикт «что нужно уточнить до принятия решения».Промпт 3. Сценарный анализ CFO
Ты — CFO, который готовит сценарный анализ для совета директоров.
Данные о компании: [выручка, EBITDA, долг, ставка кредита, ключевые операционные показатели].
Задача: построить три сценария на 2026-2027 год:
- Базовый: текущие тренды продолжаются
- Оптимистичный: рост выручки +25%, снижение ставки кредита
- Стрессовый: падение выручки -20%, рост ставки до [X]%
Для каждого сценария:
1. Определи ключевые допущения по выручке, затратам, оборотному капиталу.
2. Рассчитай EBITDA, операционный денежный поток, покрытие долга.
3. Проверь внутреннюю совместимость: переменные затраты должны меняться вместе с выручкой.
Покажи, где сценарии расходятся в допущениях и почему. Укажи, какие переменные наиболее чувствительны.
Формат: таблица сценариев + анализ ключевых рисков каждого.Промпт 4. Верификация ОДДС на ошибки
Ты — аудитор с опытом проверки отчётов о движении денежных средств.
Задача: проверить правильность ОДДС [период] на методологические ошибки.
Пройди пошагово:
1. Проверь, что операционный, инвестиционный и финансовый разделы балансируют с изменением остатка.
2. Найди статьи, которые не соответствуют разделу (например, капиталовложения в операционной части).
3. Проверь, что погашение долга в финансовом разделе совпадает с изменением долга в балансе.
4. Укажи строки, где сумма колонок не совпадает.
Показывай проверку каждого пункта явно. Если данных недостаточно — напиши, какие данные нужны.
Формат: чек-лист проверки (пройдено / ошибка / требует уточнения) + список найденных расхождений.Промпт 5. Независимая критика бюджета
Ты — независимый финансовый советник, которого попросили дать честную оценку бюджета.
Бюджет компании на 2026-2027 год: [вставить данные].
Задача: найти слабые места и необоснованные допущения.
Анализируй через три вопроса:
1. Что здесь нереалистично? (Рост выручки выше рынка без обоснования, затраты заморожены несмотря на инфляцию.)
2. Что замолчано? (Какие риски не включены в план? Какие статьи не обоснованы?)
3. Что нужно уточнить у менеджмента? (Список конкретных вопросов.)
Не смягчай критику. Цель — найти дыры, а не одобрить документ.
Формат: три блока по вопросам + рейтинг надёжности бюджета (1-10) с обоснованием.Промпт 6. Разбор договора на логические противоречия
Ты — юридический финансовый аналитик с опытом разбора сложных коммерческих договоров.
Задача: проверить [тип договора] на логические противоречия, условия, которые конфликтуют между собой, и скрытые финансовые обязательства.
Пройди пошагово:
1. Составь карту ключевых финансовых условий: суммы, сроки, ставки, штрафы, пороговые показатели.
2. Найди условия, которые противоречат друг другу в разных разделах.
3. Найди условия с нечёткими критериями, где возможна разная интерпретация.
4. Оцени финансовые риски: максимальное обязательство, условные требования, права кредитора.
Показывай ссылки на конкретные пункты для каждого вывода.
Важно: это финансовый анализ, не юридическая консультация. Флагируй вопросы для юриста отдельно.
Формат: карта рисков по разделам + список вопросов для юриста.Промпт 7. Анализ план-факта с поиском аномалий
Ты — финансовый контролёр, который делает ежемесячный план-факт анализ.
Данные план-факт за [период]: [вставить таблицу или описание].
Задача: найти значимые отклонения и их причины.
Алгоритм:
1. Отсортируй отклонения по абсолютной сумме — от большего к меньшему.
2. Для топ-5 отклонений: предложи 2-3 возможные причины для каждого.
3. Отдельно отметь статьи, где отклонение по факту противоположно плановому тренду (план рос, факт упал).
4. Найди статьи, где процентное отклонение >20%, но сумма небольшая — они часто скрывают системные проблемы.
Объясняй каждый шаг. Указывай, какие данные помогли бы уточнить причину.
Формат: таблица отклонений + нарратив «что спросить у операционного менеджмента».Промпт 8. Подготовка пояснений к отчётности для собственника
Ты — финансовый директор, который объясняет цифры собственнику без финансового образования.
Данные отчётности за [период]: [вставить ключевые показатели: выручка, EBITDA, долг, денежный поток].
Задача: написать пояснительную записку, которую поймёт собственник без финансового образования.
Принципы:
1. Ни одного термина без объяснения простыми словами.
2. Каждую цифру сопровождай контекстом: это хорошо или плохо? Почему?
3. Главный вопрос собственника всегда «сколько денег и почему»: отвечай на него в первом абзаце.
4. Заканчивай тремя вопросами, которые нужно обсудить на встрече.
Логику объяснений показывай явно. Если цифра неоднозначная — так и пиши, не причёсывай.
Формат: 3-4 абзаца на русском языке делового стиля + три вопроса для обсуждения.Три кейса: reasoning в работе реальных финансистов
Кейс 1. Финдир производства: 4 часа против 18 минут на верификации финмодели
Финдир производственного холдинга (оборот 2,2 млрд рублей) проверяла финансовую модель поглощаемого актива, подготовленную консультантами. Модель — 38 листов Excel, три сценария, DCF на 10 лет.
Обычный процесс: аналитик тратил 3-4 часа на верификацию методологии. Они запустили промпт по методу STAR-F с полным текстовым описанием модели (без конфиденциальных данных, с обезличенными суммами).
Reasoning-анализ за 18 минут выдал три критических находки:
- WACC рассчитан на структуре капитала «на момент сделки», а не на целевой структуре — занижает ставку дисконтирования на 1,8 процентных пункта.
- Терминальная стоимость составляет 78% от общей оценки — при этом ставка роста в терминальном периоде не обоснована относительно прогноза отраслевого роста.
- Прогноз выручки в оптимистичном сценарии предполагает CAGR +22% при среднеотраслевом +7%.
Аналитик проверил: все три находки подтвердились. Экономия: 3 часа 40 минут на одной сессии. Команда перестраховалась и пересчитала сделку. Оценка актива снизилась на 12%.
Кейс 2. Главбух торговой сети: план-факт за 25 минут вместо 3 часов
Главный бухгалтер федеральной розничной сети ежемесячно делала план-факт по 48 статьям в Excel. Средняя нагрузка: 3 часа разборки плюс час написания пояснений для CFO.
Она вставила обезличенную таблицу план-факт в ChatGPT с промптом 7 из этой статьи. Reasoning-анализ за 8 минут:
- Выделил 6 статей с отклонением >20% и пояснил вероятные причины по каждой
- Нашёл три статьи, где плановый тренд шёл вверх, а факт упал — «антитренды», которые вручную она замечала только через 40 минут работы
- Написал нарратив «что спросить у операционного менеджмента» — 12 конкретных вопросов
Итого на план-факт: 25 минут вместо 4 часов. Экономия в месяц: 12-14 рабочих часов. За год — полтора месяца времени.
Кейс 3. CFO инвестфонда: анализ меморандума без ночных смен
CFO небольшого инвестиционного фонда получает 3-4 инвестиционных меморандума в неделю. Раньше каждый — это вечер, 2-3 часа чтения и пометок. Reasoning-анализ по промпту 2 из этой статьи сократил первичный разбор до 35 минут.
Конкретный результат на одном меморандуме: reasoning-анализ нашёл, что скорректированный EBITDA включал «разовые» списания трёх лет подряд — то есть де-факто они были регулярными. На этом основании CFO снизил оценку на переговорах и зафиксировал условие эскроу на 18 месяцев.
Предотвращённый риск в цифрах: потенциальный overvaluation на 15-20% от суммы сделки.
Сравнение: reasoning ChatGPT vs Claude vs DeepSeek для финзадач
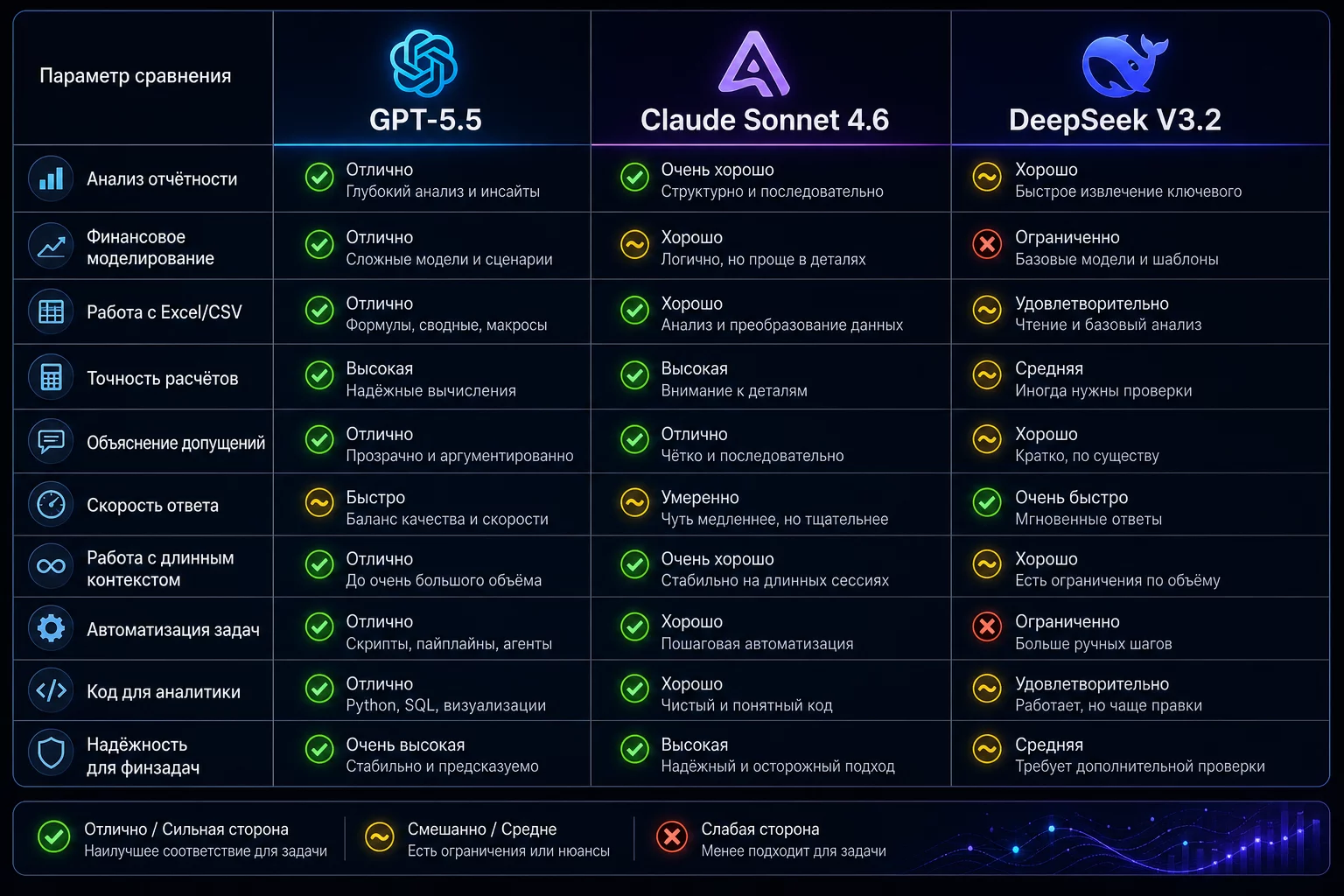
GPT-5.5, Claude Sonnet 4.6, DeepSeek V3.2: где и какой инструмент выигрывает на финансовых задачах, актуально на июнь 2026.
Актуально на июнь 2026 года. Я держу подписки на GPT-5.5 и Claude Pro одновременно — это мой базовый набор, и я не выбираю одно вместо другого.
| Параметр | GPT-5.5 (ChatGPT Plus) | Claude Sonnet 4.6 | DeepSeek V3.2 |
|---|---|---|---|
| Reasoning-глубина | встроена, высокая | встроена, очень высокая на логике | сильная, особенно математика |
| Длинные документы | до 1M токенов | до 1M токенов, аккуратнее | контекст меньше |
| Финмодель многошаговая | хорошо | отлично | хорошо на расчётах |
| Договор 50+ страниц | хорошо | отлично | хорошо |
| Таблицы и Excel-данные | отлично с Python | отлично | хорошо |
| Скорость | быстро | быстро | быстро |
| Цена | платная подписка | платная подписка | бесплатно/API |
| Доступ в России | специальные средства | специальные средства | без ограничений |
| Стиль промпта | свободный текст | XML-теги, структура | свободный |
| Агент / браузер | да | да | ограниченно |
Мой рабочий принцип: GPT-5.5 для большинства задач — первая точка входа. Claude Sonnet 4.6 беру, когда задача предполагает очень длинный документ с плотной логикой или критически важно не пропустить ни одного противоречия. DeepSeek V3.2 использую для расчётных задач и когда нет доступа к подписным сервисам. Подробнее о связке двух инструментов читайте в статье Claude для финансиста и бухгалтера.
Общий принцип для всех трёх: reasoning-качество ответа зависит от промпта больше, чем от выбора модели. Правильный промпт по методу STAR-F на DeepSeek даст лучший результат, чем небрежный запрос на GPT-5.5.
Типичные ошибки финансиста при работе с reasoning-режимом
Я видела, как через три года практики со своими ученицами одни и те же ошибки повторяются раз за разом. Reasoning-режим это не волшебная кнопка — он работает ровно настолько, насколько правильно ему поставлена задача.
Ошибка 1. «Объясни мне финансовую модель»
Это не задача для reasoning, это запрос на пересказ. Reasoning нужен, чтобы найти ошибки, проверить логику, верифицировать методологию. Запрос «объясни» даёт вам нарратив, а не анализ. Переформулируйте: «Проверь, корректна ли методология расчёта WACC, и укажи, где она расходится со стандартом CAPM».
Ошибка 2. Слишком мало контекста
«Проверь этот договор» без указания, что именно смущает, какой тип сделки, какие риски критичны. Reasoning-модель начнёт общий обзор вместо точечного анализа. Давайте контекст: «Договор конвертируемого займа, меня беспокоят условия конвертации при Down Round и триггеры досрочного погашения».
Ошибка 3. Доверять reasoning-ответу без прочтения логики
Самая опасная ошибка. Финансист смотрит на финальный вывод и принимает его за истину. Вся ценность reasoning — в цепочке рассуждений. Там могут быть допущения, с которыми вы не согласны, или шаги, которые требуют ваших данных. Читайте ход мыслей, не только итог.
Ошибка 4. Смешивать задачи в одном промпте
«Проверь финмодель, напиши пояснительную записку для собственника и составь список рисков». Три разные задачи — три разных режима работы. Reasoning на первой задаче ломается, когда её смешивают со второй. Разбивайте на отдельные запросы.
Ошибка 5. Не итерировать
Reasoning-сессия — это диалог. Первый ответ это черновик анализа. Дальше задаёте уточняющие вопросы: «А если я изменю допущение по росту выручки до 15%?», «Какой из найденных рисков самый критичный?», «Проверь только эту строку расчёта». Кто задаёт один вопрос и уходит — получает 30% потенциала инструмента.
Ошибка 6. Ждать, что reasoning сам найдёт данные
Reasoning-режим это инструмент анализа, не поиска. Если вам нужны актуальные ставки ЦБ, текущие котировки или свежая отчётность конкурента — это задача для агентного режима или Perplexity. Для reasoning все данные должны быть уже в промпте или в загруженном документе.
Про правильное использование агентного режима для сбора внешних данных читайте в статье Perplexity для финансиста.
Как o3 и o4-mini изменили стандарты качества финанализа с AI
До reasoning-моделей у финансиста был один честный вывод: ChatGPT хорошо помогает с текстом, плохо подходит для аналитики с высокой ценой ошибки. Нейросеть выдавала убедительный ответ с ошибкой внутри, и не всегда было понятно, где именно.
O3 и o4-mini сдвинули эту границу. Впервые модель начала явно показывать ход рассуждений, и финансист получил инструмент для работы с логикой, а не только с текстом. Это не значит, что reasoning-модели стали безошибочными — они ошибаются. Но они ошибаются предсказуемее и прозрачнее: если в ходе рассуждений есть спорный шаг, вы его видите и можете скорректировать.
Три изменения, которые o3/o4-mini принесли в стандарт работы:
1. Верификация как отдельный рабочий этап. Раньше нейросеть писала расчёт, финансист верил или не верил. С reasoning появился промежуточный шаг: «проверь собственный ответ, подойдя с другой стороны». Это стало стандартом для любой аналитической задачи.
2. «Не знаю» стало нормой. Reasoning-модели заметно честнее в работе с неопределённостью. «Не хватает данных для расчёта, нужно [конкретное допущение]» вместо придуманной цифры. Финансисты из нашей аудитории отмечали это как главное практическое изменение в первый месяц работы с o4-mini.
3. Аналитическая сессия, а не одиночный запрос. С reasoning стало понятно, что нейросеть — это не поисковик, а аналитический партнёр для диалога. Лучшие результаты приходят через 5-7 итераций, а не через один большой промпт.
Эти принципы перешли в GPT-5.5. Если вы работаете с нейросетями для финанализа, понимать их важнее, чем знать, какая именно модель у вас под капотом.
Когда reasoning НЕ нужен: честная граница применения
Reasoning-модели не серебряная пуля. Есть задачи, где они не дают преимущества или тратят ваше время без результата.
Reasoning излишен если:
- Задача однозначная и короткая (написать письмо, сделать конспект, перевести термин)
- Нужен творческий текст, а не аналитика (презентация для собственника в сторителлинге)
- Задача требует актуальных данных из интернета (текущие котировки, актуальные ставки) — здесь нужен режим агента, не рассуждение
- Вы хотите быстро набросать черновик — reasoning-глубина замедляет, а черновик потом всё равно переписывать
Reasoning критичен если:
- Задача многошаговая с зависимостями (изменение на шаге 5 влияет на шаги 12-18)
- Нужна верификация, а не генерация
- Ошибка в середине расчёта ломает весь результат
- Нужно найти противоречия в большом документе или между несколькими документами
- Нужны честные «не знаю» вместо придуманных цифр
Хорошее практическое правило: если вы можете проверить правильность ответа только после долгого ручного расчёта — это задача для reasoning. Если ответ очевидно верный или неверный при первом взгляде — обычный ChatGPT справится быстрее.
Как reasoning-логика работает в GPT-5.5 сегодня
GPT-5.5 в 2026 году не требует отдельного переключателя или специальной модели. Reasoning-подход активируется через структуру промпта. Чем сложнее и многошаговее задача, чем явнее вы просите показать логику, тем глубже работает внутренняя цепочка рассуждений.
Три практических способа активировать reasoning-глубину в GPT-5.5:
Способ 1. Явная просьба о шагах. Добавьте в любой аналитический промпт фразу «объясни логику каждого шага» или «покажи, как ты пришёл к этому выводу». Модель переходит в режим пошаговой верификации.
Способ 2. Просьба о независимой проверке. После получения первого ответа напишите: «А теперь проверь этот результат, подойдя к задаче с другой стороны». Reasoning-модель построит вторую цепочку и сравнит с первой. Если результаты расходятся — вы нашли ошибку.
Способ 3. Встроенный скептицизм. Формулировка «найди слабые места в этом анализе» или «что здесь может быть неверным» переключает модель в критический режим. Это мощный инструмент проверки собственных документов.
Один важный нюанс 2026 года: GPT-5.5 хорошо считает на Python без ошибок при работе с нормализованными таблицами. При загрузке Excel-файла просите «показать подробности расчёта» — модель выведет Python-код и промежуточные результаты. Это позволяет проверить вычисления, а не просто доверять числу в ответе.
Безопасность: что нельзя отправлять в ChatGPT даже с reasoning-режимом
Эта тема важна вне зависимости от глубины модели. Reasoning не меняет правила безопасности.
Правила обезличивания данных перед отправкой:
Прежде чем отправить финансовые данные в ChatGPT, пройдите по чек-листу:
- Названия контрагентов заменены на «Поставщик 1», «Покупатель 2»
- Имена сотрудников убраны или заменены на роли («Генеральный директор», «CFO»)
- Конкретные суммы округлены или пересчитаны в относительные показатели (если нужна сохранность порядка цифр — оставляйте, если нет — округляйте до миллиона)
- ИНН, расчётные счета, реквизиты банков убраны
- Данные под NDA не идут в публичный сервис вообще
В настройках ChatGPT: Settings → Data Controls → выключить «Улучшить модель для всех». Это минимум.
Для серьёзной конфиденциальности: корпоративный тариф Business с гарантией отсутствия обучения на данных, или локальная LLM на сервере компании. Подробнее об обезличивании данных читайте в статье Как обезличить финансовые данные перед отправкой в ChatGPT.
Чек-лист: когда и как использовать reasoning-подход в работе финансиста
- Оцените сложность задачи. Есть ли цепочка шагов с зависимостями? Если да — reasoning нужен.
- Обезличьте данные по чек-листу выше. Никакого NDA в публичную нейросеть.
- Напишите промпт по методу STAR-F. Не забудьте R-блок — просьбу показать логику.
- Дайте задаче контекст. Чем больше деталей о компании, задаче, допущениях — тем точнее reasoning-цепочка.
- Прочитайте ход рассуждений, не только финальный ответ. Там часто лежат допущения, которые нужно скорректировать.
- Попросите проверку с другой стороны для критически важных расчётов.
- Верифицируйте финальный результат самостоятельно. Reasoning-модель — это старший аналитик, а не замена вашей экспертизы.
- Итерируйте через уточняющие вопросы. Одна reasoning-сессия — это диалог, а не одиночный запрос.
- Сохраните эффективный промпт в папку «Промпты команды» — он работает снова и снова.
- Фиксируйте сэкономленные часы. Это ваш аргумент при следующем разговоре о подписке.
Reasoning в командной работе финотдела: как внедрить без хаоса
Личная эффективность — это хорошо. Но финотдел это команда, и если только CFO умеет составлять reasoning-промпты, а остальные получают случайные результаты, ценность инструмента теряется.
Вот минимальный набор для внедрения reasoning-подхода в команду из трёх и более человек.
Папка «Промпты команды» — общий файл (Google Docs или Confluence) с проверенными промптами под разные задачи. Структура: задача → промпт → кто и когда использовал → результат. Через месяц у вас появится библиотека из 15-20 промптов, каждый из которых уже дал реальный результат.
Правило обезличивания — написанное, а не устное. Один листок с чек-листом обезличивания (заменить контрагентов, убрать ИНН, округлить суммы) и правилом «NDA — не в публичный сервис». Обсуждение один раз, письменный стандарт навсегда.
Стандарт проверки — кто и как проверяет reasoning-анализ перед тем, как использовать в решении. Минимум: сотрудник прочитал ход рассуждений (не только итог) и может объяснить, на каком шаге основан вывод.
Шаблон задачи — стандартный бланк для разных типов запросов. Для плана-факта — свой шаблон. Для договора — свой. Для инвестзапроса — свой. Не каждый сотрудник обязан уметь составить промпт с нуля, но должен уметь заполнить шаблон.
На курсе «AI-навыки финансиста» мы даём шаблоны для всех четырёх типов задач и объясняем, как адаптировать их под отрасль и задачи конкретного финотдела. 800+ выпускников — это 800+ финотделов, у которых уже есть эта папка. Многие присылают в канал @findir_pro скриншоты, как промпт из курса сэкономил им несколько часов на конкретной задаче.
Небольшой принципиальный момент: reasoning-инструменты хорошо встраиваются в работу команды именно потому, что показывают логику. Когда один сотрудник приходит к CFO с «нейросеть сказала» — это слабый аргумент. Когда он приходит с «вот ход рассуждений модели, вот шаги, которые я проверил, вот где потенциальная ошибка в меморандуме» — это профессиональный финансовый анализ, усиленный AI.
Reasoning и GPT-агенты: что дальше
Следующий шаг после освоения reasoning-промптов — GPT-агенты с reasoning-логикой внутри. Агент не просто думает перед ответом: он самостоятельно ходит по сайтам, собирает данные, верифицирует их и строит аналитику в один запуск.
Пример для CFO: «Собери данные по кредитным ставкам для МСБ в пяти крупнейших банках, сравни условия, рассчитай, какой из них оптимален для рефинансирования при нашем профиле долга, и подготовь таблицу для презентации правлению». Два часа работы аналитика — 20 минут в режиме агента с reasoning.
О создании кастомных GPT-агентов с reasoning-логикой читайте в статье GPT-агенты для финансиста: как создать команду AI-сотрудников. Если интересно, как reasoning-подход работает в автоматизации через n8n — смотрите материал n8n для финансиста.
Каналы школы «Финансовый директор | Мастер CFO»:
- Telegram-канал @findir_pro — 45 000 финансистов, ежедневные разборы AI-инструментов
- Канал «АИ с Софьей и Натали» — 13 000, живые кейсы и разборы с основателем школы Софьей Бурцевой и мной
- Сообщество MAX — 5 000+ участников, практика, шаблоны, живые сессии
Натали Васильева — эксперт по нейросетям и продюсер онлайн-школы «Финансовый директор | Мастер CFO». Работает с нейросетями с февраля 2023 года. Через курс «AI-навыки финансиста» прошли 800+ финансистов и главных бухгалтеров.