AI для финансиста
Сверка регистров через ChatGPT Code Interpreter: автоматизация за 30 минут
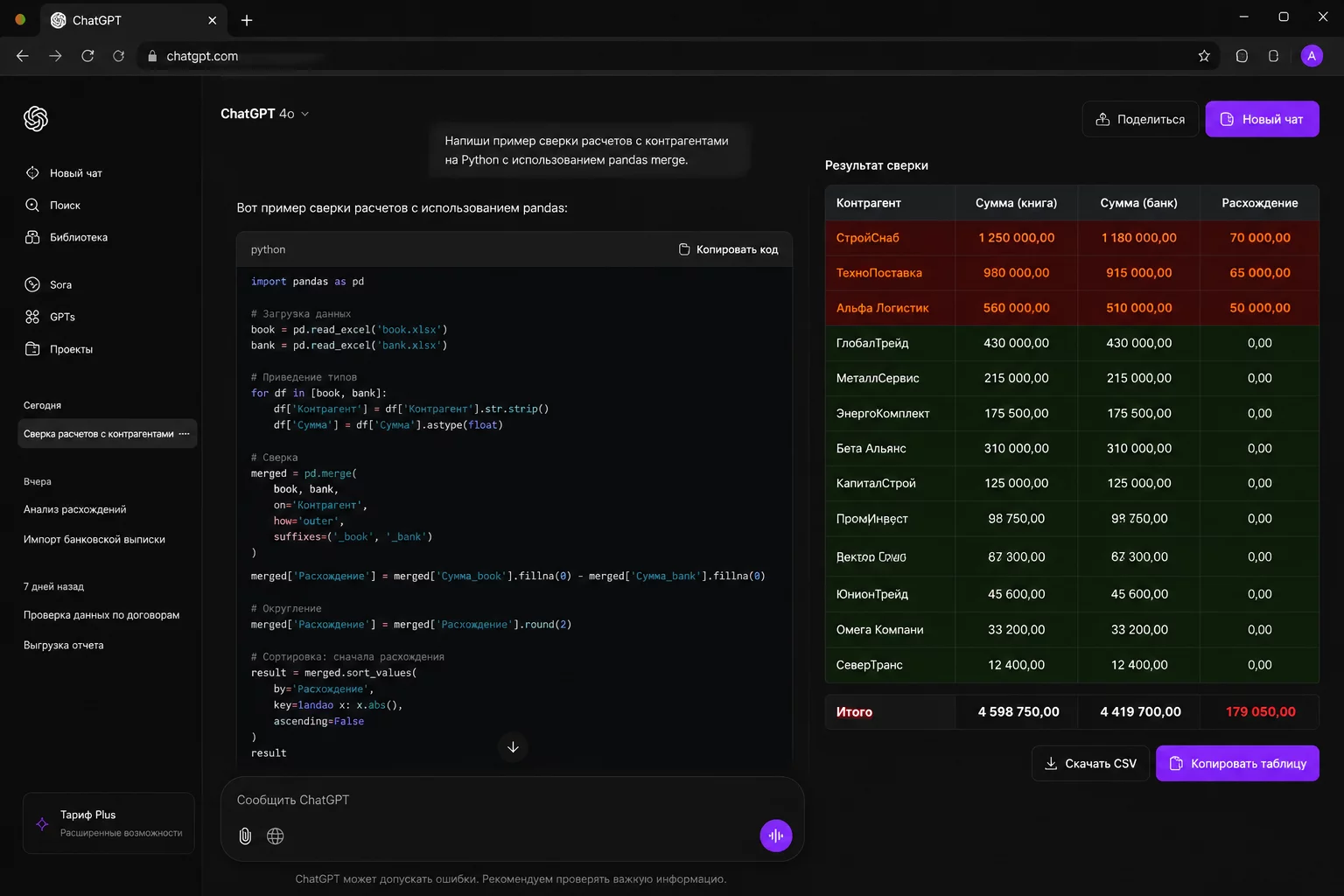
Сверка дебиторки за май: выгрузка из 1С на 1 300 строк, банковская выписка на 900 операций, и где-то в этом массиве живут расхождения. Вручную это 4-6 часов, ВПР в Excel, усталые глаза к шести вечера и три «непонятных» строки, которые откладываешь на потом. С ChatGPT Code Interpreter та же задача занимает 30 минут, и не потому что нейросеть умнее вас, а потому что Python считает быстрее и не устаёт. Я Натали Васильева, эксперт по нейросетям и продюсер онлайн-школы «Финансовый директор | Мастер CFO» (45 000 подписчиков в @findir_pro, 800+ выпускников курса AI-навыков). Три с половиной года работаю с нейросетями на финансовых задачах — 800+ финансистов прошли через этот метод в нашей школе, я видела все типичные грабли первой сверки и знаю, где ломается у всех. Внутри статьи: что такое Code Interpreter, пошаговая инструкция, 10 готовых промптов, три кейса с реальными цифрами экономии, сравнение с Excel и встроенными отчётами 1С, правила безопасности и чек-лист. Актуально по состоянию на 4 июня 2026 года.
Откуда берётся 4-6 часов на сверку дебиторки
Типовая сверка в финотделе выглядит так. Открываешь выгрузку из 1С: 800 строк по счёту 62, дата, контрагент, номер договора, сумма. Открываешь банковскую выписку: 450 операций, дата поступления, назначение платежа, сумма. Нужно свести эти два мира и найти что оплачено, что нет, где переплата, где задвоение. Стандартный путь: ВПР в Excel или сводная таблица с несколькими этапами нормализации.
Проблема не в инструментах, а в ошибках и потраченном времени. ВПР работает пока форматы совпадают. Стоит банку написать «ООО Ромашка» вместо «ООО “Ромашка”» в кавычках, и строка выпадает из сверки незаметно. Человеческий глаз на тысяче строк пропускает расхождения — особенно к концу монотонной работы в конце квартала, и каждое пропущенное расхождение превращается в «непонятный» остаток на счёте.
Что такое Code Interpreter в ChatGPT и как он работает
Определение одним предложением: Code Interpreter это встроенный Python-интерпретатор внутри ChatGPT, среда исполнения кода прямо в чате без установки чего-либо на ваш компьютер.
Технически это изолированная песочница, в которой ChatGPT генерирует Python-код под вашу задачу и сразу выполняет его. ChatGPT Plus (GPT-5.5, актуальная версия на дату публикации) хорошо понимает задачи на русском языке, пишет корректный код с библиотекой pandas для работы с таблицами и умеет самостоятельно отлаживать ошибки в нескольких итерациях.
Что Code Interpreter умеет для задач финансиста:
- Читать Excel с одним или несколькими листами, CSV, TXT с разными разделителями
- Нормализовать данные перед сравнением: убрать лишние пробелы, привести суммы из текста в числа, унифицировать формат дат
- Искать совпадения между двумя таблицами по одному или нескольким ключам
- Считать расхождения с точностью до копейки
- Находить дубли и задвоения внутри одного реестра
- Выгружать результат в Excel для скачивания
- Строить графики расхождений по запросу
Что Code Interpreter не умеет: проверять нормы НК на актуальность, подписывать акты сверки, подключаться к 1С напрямую, выходить в интернет во время выполнения кода.
Как это выглядит в интерфейсе: в ChatGPT Plus рядом с полем ввода есть кнопка прикрепления файла. Загружаете файл, ChatGPT читает данные и показывает первые строки. Вы пишете задачу. ChatGPT формулирует подход, пишет код, выполняет его и выдаёт результат. Если что-то пошло не так, модель сама переписывает код и пробует снова: это занимает ещё 30-60 секунд.
Важный нюанс по объёму данных: Code Interpreter принимает файлы до 512 МБ и стабильно работает с регистрами до 100 000 строк. Для большинства бухгалтерских задач (выписка за месяц, квартал, ОСВ по одному субсчёту) этого более чем достаточно. Если файл тяжелее, агрегируйте данные в 1С перед выгрузкой.
Анатомия ручной сверки: из чего складываются часы
Откуда конкретно берётся это время — по шагам.
Первый кусок потерь: выгрузка и нормализация. Из 1С нужно выгрузить ОСВ в нужном разрезе, убрать промежуточные итоги, проверить что суммы числовые, а не текстовые. Из банка нужно скачать выписку в правильном формате, найти и убрать строки с кредитовыми операциями если нужны только поступления. Это 30-60 минут при аккуратной работе.
Второй кусок потерь: нормализация перед сравнением. Контрагент в 1С записан как «ООО Контрагент», в банке как «ООО “КОНТРАГЕНТ”». ВПР их не найдёт без ручной нормализации. Суммы могут отличаться на копейки из-за округления при конвертации. Даты в разных форматах. Убрать это руками на тысяче строк это ещё 60-90 минут.
Третий кусок потерь: разбор пограничных случаев. Частичная оплата в два транша. Один платёж закрывает два счёта. Задержка на два дня из-за банковских выходных. Каждый нестандартный случай требует ручного разбора и занимает 5-15 минут.
Четвёртый кусок потерь: снижение концентрации. К третьему часу монотонной работы с таблицами вероятность пропустить расхождение резко растёт. Именно поэтому «3-5 непонятных строк», которые остаются после каждой ручной сверки, это не случайность, а системная проблема.
Code Interpreter закрывает первые три куска потерь полностью. Четвёртый исчезает сам: нейросеть не устаёт. Итог в цифрах: дебиторка с банком — 4-6 часов вручную против 30 минут; ОСВ по счёту 60 с реестром входящих счетов — 3-4 часа против 20 минут; поиск задвоений — от 2 часов до 10 минут; сверка актов с 8 поставщиками — полный рабочий день против 2,5 часа.
Какие типы сверок закрывает Code Interpreter за 30 минут
Прямой ответ: четыре основных типа, которые составляют большую часть рутины финансиста и бухгалтера.
Тип 1. Дебиторка с банковской выпиской. Сравниваете счета, выставленные контрагентам (из 1С, счёт 62), с фактическими поступлениями из банка. Ищете неоплаченные счета, переплаты, задвоенные поступления.
Тип 2. Кредиторка с реестром входящих счетов. Сравниваете выставленные поставщиками счета (счёт 60) с платежами из выписки. Находите счета без оплаты, оплаты без подтверждающего счёта, задвоенные авансы.
Тип 3. ОСВ с актом контрагента. Берёте акт взаиморасчётов от контрагента и сравниваете с вашими данными за тот же период. Находите разницы и структурируете позицию для переговоров.
Тип 4. Платёжный календарь план-факт. Сравниваете плановые платежи из платёжного календаря с фактическими из банковской выписки. Видите исполненные в срок, с задержкой и неисполненные.
Помимо этих четырёх типов Code Interpreter справляется с поиском дублей внутри одного реестра и с проверкой соответствия документов: например, каждый акт должен иметь счёт-фактуру с той же суммой.
Как подготовить файлы перед загрузкой в ChatGPT
Три обязательных шага, без которых Code Interpreter получает мусор на входе и выдаёт мусор на выходе.
Шаг 1. Обезличивание. Это не опция, это требование. Реальные ИНН, полные названия контрагентов, банковские реквизиты, ФИО ответственных в публичную нейросеть не загружаем. Налоговая тайна и персональные данные это зона вашей ответственности, не ChatGPT.
Как обезличить быстро: создайте в Excel справочник замен из двух колонок — реальное название и маска. «ООО Контрагент А» становится «Контрагент 1», ИНН 7712345678 становится «К01». Через Ctrl+H (Найти и заменить) замените реальные названия на маски во всём файле. Суммы округлять не нужно, точность для сверки важна.
Шаг 2. Нормализация формата. Code Interpreter умеет чистить данные, но лучше помочь ему заранее. Три вещи проверяете руками:
- Суммы в числовом формате, не текстовом: если ячейка выравнивается по левому краю, это текст
- Даты в одном формате в обоих файлах: предпочтительно ДД.ММ.ГГГГ
- Заголовки колонок в первой строке, без пустых строк в начале файла и без объединённых ячеек в шапке
Шаг 3. Определите ключ сравнения. По какому полю сравнивать два файла? Идеальный ключ: уникальный номер документа. Хороший ключ: контрагент плюс сумма плюс дата. Плохой ключ: только контрагент, у одного контрагента могут быть десятки операций за месяц. Напишите ключ в промпте явно, иначе ChatGPT будет угадывать.
Практический совет: первую сверку делайте на небольшом файле в 50-100 строк. Убедитесь что логика работает и расхождения находятся верно, потом загружайте полный массив.
Как выгрузить данные из 1С и банка для сверки в ChatGPT
Качество выгрузки определяет качество результата. Разберу три основных сценария.
Выгрузка ОСВ из 1С: Бухгалтерия
Путь: «Отчёты» > «Стандартные отчёты» > «Оборотно-сальдовая ведомость по счёту». Перед формированием в «Настройках» выбираем: «Группировка» по документам, «Показывать счета» с детализацией по субконто. Убираем «Промежуточные итоги по датам» если есть.
Ключевой момент: итоговые строки в выгрузке мешают Code Interpreter. Перед загрузкой в ChatGPT удалите строки «Итого» или в промпте напишите: «Исключи строки где поле “Контрагент” пустое или содержит “Итого”».
После формирования: «Сохранить» > «Формат Excel». Не PDF, именно Excel.
Выгрузка банковской выписки
Большинство российских банков дают выписку в Excel, CSV или PDF. Для Code Interpreter берите Excel или CSV. PDF читается плохо.
В онлайн-банке: «История операций» > выбрать период > формат Excel > скачать. До скачивания отфильтруйте только поступления, если нужна сверка дебиторки. Проверьте что выписка содержит колонку назначения платежа, часть банков скрывает её в «упрощённом» формате.
Когда в 1С неудобная структура
Если ОСВ выгружается с многоуровневой иерархией и объединёнными ячейками в шапке, попробуйте «Карточку счёта» вместо ОСВ: она даёт строку на каждую проводку без иерархии и лучше читается в Code Interpreter.
Или напишите в промпте: «Файл имеет иерархическую структуру. Оставь только строки с датой и суммой, убери строки-заголовки групп и итоговые строки».
Пошаговая сверка дебиторки с банковской выпиской за 30 минут
Разберу конкретный пример. Исходные данные: выгрузка из 1С по счёту 62.01 за май 2026 года и банковская выписка за май в Excel.
Этапы работы:
0-5 минут. Подготовка файлов. Выгружаем ОСВ из 1С (счёт 62.01, период май, группировка по контрагентам и документам). Скачиваем банковскую выписку, фильтруем только поступления. Обезличиваем оба файла по справочнику. Проверяем форматы. Сохраняем как .xlsx.
5-7 минут. Открываем ChatGPT Plus и загружаем файлы. Новый чат на chatgpt.com. Через кнопку прикрепления загружаем оба файла. ChatGPT показывает первые строки каждого файла. Проверяем что данные прочитаны правильно: если суммы показаны как «object» вместо числа, это текстовый формат, нужна доработка.
7-20 минут. Запускаем сверку промптом. Пишем задачу с описанием структуры файлов и ключа сравнения (промпт 1 из раздела ниже). ChatGPT пишет код, выполняет его, выдаёт таблицу расхождений с тремя разделами: совпадения, только в 1С, только в банке.
20-25 минут. Уточняем и разбираем. Задаём уточняющие вопросы: «Покажи топ-10 расхождений по сумме», «Почему у Контрагента 3 нет пары в банке?». ChatGPT помнит загруженные файлы в рамках сессии.
25-30 минут. Скачиваем результат и сохраняем код. «Сохрани таблицу расхождений как Excel-файл для скачивания». Скачиваем файл, проверяем итоговые суммы, копируем Python-код в библиотеку.
Что происходит внутри: Python-код, который пишет ChatGPT
Многие финансисты боятся Code Interpreter, потому что не понимают что именно происходит «за кулисами». Разберу типичный сеанс сверки шаг за шагом.
Этап 1. ChatGPT читает файл и описывает структуру.
После загрузки ChatGPT разбирает структуру файла: количество строк, заголовки колонок, тип данных в каждой колонке. Часто в первом ответе он пишет: «Файл прочитан успешно. Вот первые строки» и показывает таблицу.
Это важная контрольная точка. Если ChatGPT написал что колонка «Сумма» имеет тип object вместо float64, значит данные записаны как текст и расчёты будут неверными. Скажите: «Колонка Сумма прочитана как текст. Очисти пробелы как разделители тысяч, преобразуй в числовой формат и продолжи».
Этап 2. ChatGPT пишет и выполняет Python-код.
После вашего промпта появляется блок «Выполняется код». Внутри — Python с библиотекой pandas. Типичная сверка двух файлов через merge выглядит так:
import pandas as pd
# Загрузка файлов
df_1c = pd.read_excel("62_mai.xlsx")
df_bank = pd.read_excel("bank_mai.xlsx")
# Нормализация перед сравнением
df_1c["Контрагент"] = df_1c["Контрагент"].str.strip().str.upper()
df_bank["Контрагент"] = df_bank["Контрагент"].str.strip().str.upper()
df_1c["Кредит"] = pd.to_numeric(df_1c["Кредит"], errors="coerce")
df_bank["Сумма_прихода"] = pd.to_numeric(df_bank["Сумма_прихода"], errors="coerce")
# Создание ключа сравнения: контрагент + сумма (округление до рубля)
df_1c["Ключ"] = df_1c["Контрагент"] + "_" + df_1c["Кредит"].round(0).astype(str)
df_bank["Ключ"] = df_bank["Контрагент"] + "_" + df_bank["Сумма_прихода"].round(0).astype(str)
# Сверка через outer merge
merged = pd.merge(df_1c, df_bank, on="Ключ", how="outer", indicator=True)
# Три раздела результата
matches = merged[merged["_merge"] == "both"]
only_1c = merged[merged["_merge"] == "left_only"]
only_bank = merged[merged["_merge"] == "right_only"]
print(f"Совпадения: {len(matches)} строк, сумма {matches['Кредит_x'].sum():,.0f} руб")
print(f"Только в 1С: {len(only_1c)} строк, сумма {only_1c['Кредит_x'].sum():,.0f} руб")
print(f"Только в банке: {len(only_bank)} строк, сумма {only_bank['Сумма_прихода'].sum():,.0f} руб")Вам не нужно понимать каждую строку. Главное: если ключ сравнения в промпте указан верно, результат будет верным. Код виден в диалоге и его можно проверить или попросить ChatGPT объяснить любую строку по-русски.
Этап 3. Уточняющий диалог.
После первого результата начинается самое интересное: диалог. «Покажи топ-5 расхождений по сумме», «Сгруппируй раздел “Только в банке” по контрагентам», «Почему итог по разделу совпадений меньше суммы кредитовых оборотов из 1С?». ChatGPT запускает дополнительный код под каждый вопрос и объясняет результат.
Типичная сессия сверки: 10-15 шагов диалога. Загрузка, первый просмотр структуры, запуск сверки, 5-6 уточняющих вопросов, запрос на сохранение файла. Это принципиально отличается от Excel, где вы строите формулы самостоятельно.
Десять готовых промптов для сверки регистров
Все промпты работают в ChatGPT Plus с GPT-5.5. Перед каждым промптом загружайте соответствующие файлы через кнопку прикрепления. Текст в [КВАДРАТНЫХ СКОБКАХ] заменяйте на свои данные.
Промпт 1. Сверка дебиторки с банковской выпиской
Я загрузила два файла:
1. "[ФАЙЛ_1С].xlsx" — ОСВ из 1С по счёту 62.01 за [ПЕРИОД].
Колонки: Контрагент, Документ, Дата, Дебет (начислено),
Кредит (оплачено), Сальдо.
2. "[ФАЙЛ_БАНК].xlsx" — банковская выписка, только поступления.
Колонки: Дата, Назначение_платежа, Контрагент, Сумма_прихода.
Задача: сверить поступления в банке с кредитовыми оборотами по 62.01.
Ключ сравнения: Контрагент + Сумма (допуск ±1 руб на округление).
Результат: три раздела:
1. Совпадения (Контрагент, Сумма, Дата в 1С, Дата в банке)
2. Есть в банке, нет в 1С (Контрагент, Сумма, Дата)
3. Есть в 1С, нет в банке (Контрагент, Сумма, Дата начисления)
Итоговые суммы по каждому разделу.
Перед сверкой покажи первые 5 строк каждого файла и типы колонок.
Сохрани результат как Excel-файл для скачивания.Промпт 2. Сверка кредиторки с реестром входящих счетов
Файл "[ОСВ_60].xlsx" — ОСВ из 1С по счёту 60.01 за [ПЕРИОД].
Колонки: Контрагент, Документ, Дата, Дебет (оплачено),
Кредит (начислено), Сальдо.
Файл "[РЕЕСТР_СЧЕТОВ].xlsx" — реестр входящих счетов от поставщиков.
Колонки: Контрагент, Номер_счёта, Дата, Сумма.
Найди три типа расхождений:
1. Счета в реестре без оплаты в 1С
2. Оплаты в 1С без соответствующего счёта в реестре
3. Задвоения: одинаковые Контрагент + Сумма встречаются дважды
в пределах 5 дней
Ключ сравнения: Контрагент + Сумма (допуск ±1 руб).
Отсортируй расхождения по убыванию суммы.
Итоговые суммы и количество строк по каждому типу.Промпт 3. Поиск задвоений и аномалий внутри реестра
Файл "[ПЛАТЕЖИ].xlsx" — журнал платежей за [ПЕРИОД].
Колонки: Дата, Контрагент, Номер_документа, Сумма, Статья_затрат.
Найди три типа проблем:
1. Полные дубли: одинаковые Контрагент + Номер_документа + Сумма
2. Возможные задвоения: одинаковые Контрагент + Сумма
в пределах 3 дней (разные документы)
3. Аномально крупные суммы: больше 3 стандартных отклонений
от среднего по той же Статье_затрат
Для каждого дубля показывай строки-кандидаты рядом.
Итоговые суммы по каждому типу проблем.Промпт 4. Сверка ОСВ с актом контрагента
Файл "[ОСВ_контрагент].xlsx" — наши данные по [НАЗВАНИЕ_МАСКИ]
из 1С за [ПЕРИОД].
Колонки: Дата, Номер_документа, Дебет, Кредит.
Файл "[АКТ_контрагент].xlsx" — акт сверки от контрагента
за тот же период.
Колонки: Дата, Номер_документа, Сумма_по_данным_поставщика.
Сравни по ключу Номер_документа. Найди:
1. Документы у нас, которых нет в акте контрагента
2. Документы в акте, которых нет у нас
3. Документы в обоих файлах с расходящимися суммами
Итого: сумма расхождения по нашим данным и по данным контрагента.
Общее сальдо по каждой версии.Промпт 5. Сверка авансовых платежей по счёту 76
Файл "[АВАНСЫ].xlsx" — выгрузка по счёту 76 «Авансы выданные»
за [ПЕРИОД].
Колонки: Контрагент, Договор, Дата_аванса, Сумма_аванса,
Дата_закрытия, Сумма_закрытия.
Найди:
1. Авансы без закрывающего документа (Дата_закрытия пустая)
2. Авансы закрытые не полностью (Сумма_закрытия < Сумма_аванса)
3. Авансы, которые висят дольше [СРОК_ДНЕЙ] дней от Даты_аванса
Итого по каждой категории: количество и суммарная сумма.
Отсортируй по убыванию срока давности аванса.Промпт 6. Сверка налоговых платежей с данными из ЕНС
Файл "[ЕНС].xlsx" — выписка по Единому налоговому счёту
за [ПЕРИОД].
Колонки: Дата, Тип_операции, Сумма, Основание.
Файл "[НАЧИСЛЕНИЯ].xlsx" — реестр начисленных налогов из 1С.
Колонки: Налог, Период_начисления, Сумма_начисления, Срок_уплаты.
Проверь, все ли начисленные налоги уплачены через ЕНС.
Ключ сравнения: Налог + Период + Сумма (допуск ±100 руб).
Найди:
1. Начисленные налоги без платежа в ЕНС
2. Платежи в ЕНС без начисления в реестре
3. Уплаты с нарушением срока (Дата_платежа > Срок_уплаты)
Итого: общая сумма недоплат и просрочек.Промпт 7. Платёжный календарь: план vs факт
Файл "[ПЛАН].xlsx" — платёжный календарь на [ПЕРИОД].
Колонки: Дата_план, Контрагент, Назначение, Сумма_план.
Файл "[ФАКТ].xlsx" — фактические платежи из банковской выписки.
Колонки: Дата_факт, Контрагент, Назначение, Сумма_факт.
Сравни по ключу Контрагент + Сумма (допуск ±500 руб).
Покажи четыре группы:
1. Исполнено в срок (отклонение по дате до 2 дней)
2. Исполнено с задержкой (больше 2 дней)
3. Плановые платежи, не исполненные на дату анализа
4. Фактические платежи без плана
Итого: процент исполнения по количеству и по сумме.Промпт 8. Анализ причин расхождений после сверки
Файл "[РАСХОЖДЕНИЯ].xlsx" — результат сверки.
Колонки: Контрагент, Тип_расхождения, Наша_сумма,
Их_сумма, Разница.
Для каждого расхождения предложи наиболее вероятную причину:
- Ошибка периода (операция попала в другой месяц)
- Разная дата признания (отгрузка vs платёж)
- Банковская комиссия или округление
- Неоплаченный аванс
- Задвоение документа
- Частичная оплата несколькими платежами
Расставь объяснения по каждой строке.
Топ-10 самых крупных расхождений по абсолютной сумме выдели отдельно.Промпт 9. Проверка структуры файла перед сверкой
Я загрузила файл "[ФАЙЛ].xlsx" для подготовки к сверке.
Проверь и сообщи:
1. Сколько строк данных (без заголовка)?
2. Какие колонки и типы данных?
3. Есть ли пустые значения в ключевых колонках?
4. Суммы числового типа или текст?
5. В каком формате записаны даты?
6. Есть ли строки-итоги (слова "Итого", "Итог" в любой колонке)?
Если найдены проблемы, предложи код их исправления.
Покажи первые 10 строк файла.Промпт 10. Сохранение результата и Python-кода для повторного использования
Ты только что провёл сверку двух файлов и получил таблицу расхождений.
Сделай три вещи:
1. Сохрани итоговую таблицу расхождений как Excel-файл
"[НАЗВАНИЕ_РЕЗУЛЬТАТА].xlsx" для скачивания.
2. Выведи полный Python-код, который ты использовал для сверки,
в отдельном блоке с комментариями на русском языке.
3. В начале кода добавь переменные которые нужно менять каждый месяц:
FILE_1 = "название_файла_1.xlsx"
FILE_2 = "название_файла_2.xlsx"
PERIOD = "май 2026"
Остальной код должен работать без изменений при смене этих трёх переменных.Хочешь готовый шаблон справочника обезличивания и все 10 промптов одним файлом? Забирай бесплатно в Telegram-канале школы @findir_pro. Там же каждую неделю разбираем новые AI-инструменты для финансистов.
Три кейса с цифрами: сколько времени и денег экономит финансист
Кейс 1. Главбух дистрибьюторской компании, Москва
Было: ежемесячная сверка дебиторки с банковской выпиской. 180 контрагентов, 1 400-1 600 операций в месяц. Инструмент: ВПР в Excel вручную. Время: 5-6 часов в последний рабочий день месяца. Дополнительная проблема: каждый месяц оставались 3-4 «необъяснённых» расхождения на общую сумму 30 000-200 000 рублей, которые откладывались «разобраться на следующей неделе».
Что сделали: настроили выгрузку ОСВ по счёту 62.01 в стандартном формате, создали справочник обезличивания для 180 контрагентов (один раз за 40 минут), написали шаблон промпта под этот тип сверки.
Первая попытка сломалась на форматах: банк выгружал суммы с неразрывными пробелами как разделителями тысяч, и Code Interpreter читал их как текст — merge не давал ни одного совпадения при 1 400 строках. Разобрались за 15 минут: добавили в промпт «очисти разделители тысяч и преобразуй суммы в числовой тип перед сверкой». С тех пор эта строка стоит в шаблоне по умолчанию.
Стало: те же 1 400 строк за 30 минут. Итоговый файл с тремя разделами, все расхождения найдены. Через три месяца стала делать промежуточную сверку 15-го числа, которой раньше не было: слишком дорого по времени.
Экономия: 5-5,5 часа в месяц. Ноль «отложенных» несоответствий: все расхождения нашли и разобрали за одну сессию.
Кейс 2. Финансовый директор производственного предприятия, Екатеринбург
Было: квартальная сверка взаиморасчётов с 8 ключевыми поставщиками. Один поставщик — 1-1,5 часа: скачать акт в PDF, перебить в Excel, сверить с данными 1С вручную. Восемь поставщиков — полный рабочий день. Регулярно выходил на переговоры с поставщиком «примерно понимая» позицию.
Что сделали: договорились с поставщиками получать акты в Excel, а не PDF. Настроили выгрузку из 1С в формате карточки счёта по каждому контрагенту. Написали промпт 4 из нашей библиотеки.
Стало: 15-20 минут на одного поставщика (подготовка файла + промпт + разбор). Все 8 поставщиков за 2,5 часа. Практическая польза сверх экономии времени: на переговоры идёт с детальной таблицей расхождений в разрезе каждого документа. Перестал соглашаться на «ну давайте округлим».
Экономия: 5-6 часов в квартал. Три спора закрыты в пользу компании с суммарным итогом 180 000 рублей за полгода: детальная таблица расхождений по каждому документу убирала торг о том, кто прав.
Кейс 3. Бухгалтер аутсорсинговой компании, Санкт-Петербург
Было: ведёт 12 организаций. Каждому в конце месяца нужна сверка ЕНС с начисленными налогами. По 30-40 минут на организацию = целый рабочий день только на ЕНС. Регулярно что-то пропускалось: начислили налог, уплату в ЕНС не сверили, срок прошёл.
Что сделали: написали шаблон промпта 6 для сверки ЕНС. Для каждой организации стандартная выгрузка двух файлов (ЕНС и начисления из 1С).
Стало: каждая организация 8-10 минут. Все 12 за 2 часа. В отчёте Code Interpreter есть раздел «просроченные уплаты» с конкретными суммами и датами. Ноль пропущенных сроков ЕНС за четыре месяца после внедрения.
Экономия: 6 часов в месяц. Ноль пропущенных сроков ЕНС за 4 месяца. При стоимости часа специалиста 2 500 рублей — 15 000 рублей экономии трудозатрат в месяц.
Code Interpreter vs Excel vs встроенные отчёты 1С: сравнение для финансиста
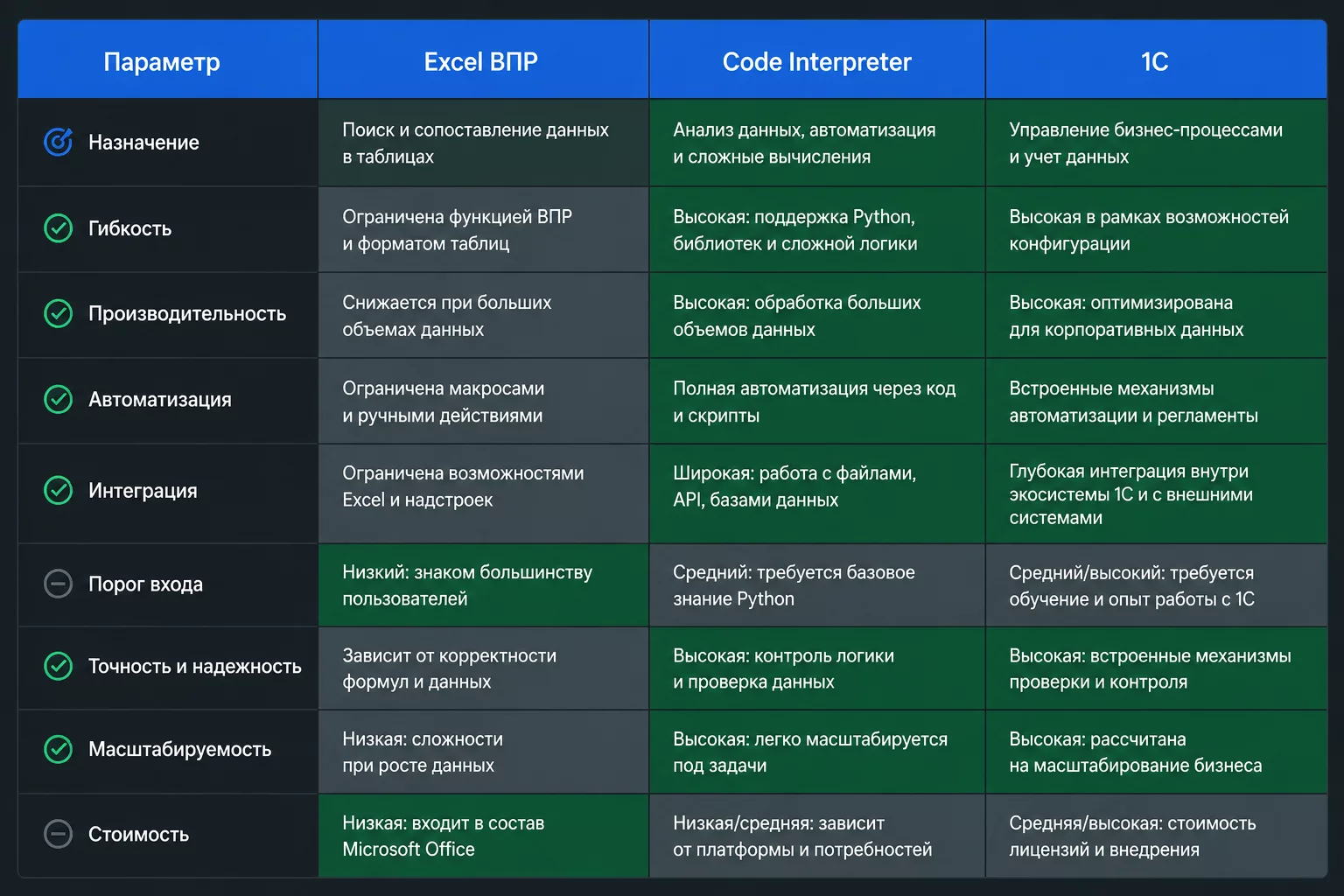
| Параметр | Excel (ВПР / Power Query) | Code Interpreter в ChatGPT | Встроенные отчёты 1С |
|---|---|---|---|
| Скорость первой настройки | 20-40 мин | 5-10 мин (промпт + загрузка) | 0 (готово из коробки) |
| Скорость на 1 000 строк | 10-30 мин | 2-5 мин | 1-3 мин |
| Данные из нескольких источников | Требует нормализации вручную | Python нормализует автоматически | Только данные 1С |
| Объяснение расхождений | Нет | Есть, по-русски | Нет |
| Повторное использование | Файл с формулами | Сохранённый Python-код | Готовый отчёт |
| Стоимость | Входит в Office | ChatGPT Plus: от 20 USD/мес | В составе лицензии 1С |
| Нужно обезличивать | Не нужно | Нужно | Не нужно |
| Данные банка и внешних систем | Да | Да | Нет |
| Порог вхождения | Средний (нужен ВПР) | Низкий (промпт на русском) | Низкий (готовые отчёты) |
Актуально на июнь 2026 года.
Практический вывод: встроенные отчёты 1С подходят для сверок внутри одного контура. Excel отлично работает для простых двухколоночных сверок при нормализованных данных. Code Interpreter выигрывает когда нужно сравнить несколько источников данных с разными форматами или получить объяснение расхождений по-русски.
Как разобрать расхождения: диалог с ChatGPT после сверки
Найти расхождение и понять его причину — это две разные задачи. Code Interpreter хорошо справляется с первой, а ChatGPT как текстовая модель помогает со второй.
После получения таблицы расхождений задаю ChatGPT четыре типа вопросов.
Вопрос на причину. «По Контрагенту 3 в 1С показано 450 000 рублей, в банке 445 000, разница 5 000. Какие наиболее типичные причины такого расхождения в российском бухучёте?» ChatGPT предложит варианты: банковская комиссия, оплата частями, ошибка периода, округление при конвертации.
Вопрос на проверку кода. «Покажи полный Python-код, который ты выполнил для поиска расхождений. Объясни логику операции merge.» Вы видите логику и убеждаетесь что в ключе сравнения нет ошибки.
Вопрос на группировку. «Сгруппируй расхождения по типу: разные суммы при совпадающем контрагенте vs строка отсутствует в одном из файлов. По каждому типу покажи количество и суммарную сумму.»
Вопрос на приоритизацию. «Отсортируй расхождения по убыванию абсолютной суммы. Выдели топ-10 для первоочередного разбора.»
Важное правило: ChatGPT объясняет возможные причины на основе типичных ситуаций. Конкретную причину конкретного расхождения знаете только вы. Нейросеть сужает круг версий, финальное решение принимает финансист.
Что загружать в ChatGPT безопасно, а что нельзя: правила и правовая база
Финансовая информация — зона повышенной ответственности, и я проговариваю эти правила с каждой ученицей на первом занятии.
Нельзя загружать в публичный ChatGPT:
- Реальные ИНН организаций и физических лиц
- Полные названия контрагентов, по которым можно идентифицировать компанию
- Банковские реквизиты: расчётные счета, БИК, корреспондентские счета
- ФИО сотрудников и должностных лиц
- Точные данные по сделкам, составляющим банковскую тайну или предмет жёсткого NDA
Можно с обезличиванием:
- Структуру транзакций с масками вместо реальных контрагентов
- Реестры с заменёнными реквизитами по справочнику замен
- Агрегированные суммы по периодам без привязки к конкретным компаниям
Можно свободно:
- Тестовые данные, сгенерированные вами
- Структуру таблицы без реальных значений
- Демо-выгрузки из тестовой базы 1С
Две технические настройки, которые нужно проверить прямо сейчас: в Settings > Data Controls выключите тумблер «Улучшить модель для всех». Это запрещает OpenAI использовать ваши чаты для обучения модели. Если данные стратегически важны, используйте ChatGPT Business (25 USD на пользователя в месяц): изолированный корпоративный контур.
Правовая база: за что отвечает финансист
Российское законодательство в 2026 году различает три режима данных, которые финансист обрабатывает ежедневно.
Персональные данные (ФЗ-152). ФИО, ИНН физлица, зарплата, адрес, телефон это персональные данные. Их передача иностранному оператору без законного основания нарушает ФЗ-152 и создаёт состав по ст. 13.11 КоАП РФ. С 2025 года за утечки персональных данных действуют оборотные штрафы: за повторные нарушения — от 1 до 3% выручки, не менее 20 млн рублей; за первичные нарушения — фиксированный штраф от 3 до 20 млн рублей в зависимости от объёма данных. Ответственность наступает за сам факт неправомерной передачи, не только за доказанную утечку. Загрузили зарплатную ведомость с фамилиями в публичную нейросеть: уже нарушение.
Банковская тайна (ФЗ «О банках и банковской деятельности»). Данные об операциях, остатках и условиях кредитов охраняются законом о банковской тайне. Разглашение банковской тайны это потенциально уголовная ответственность для виновного лица. Поэтому такие данные не идут в публичное облако ни при каком обезличивании.
NDA и коммерческая тайна. Если в соглашении о неразглашении есть запрет передавать информацию третьим лицам, то загрузка документа в ChatGPT это нарушение договора само по себе, даже без утечки. Ответственность: дисциплинарная, материальная, вплоть до иска о возмещении убытков.
Доступ к chatgpt.com из России требует специальных средств. Каким способом подключаться, каждый решает сам с учётом задач и требований к безопасности: инструкций по обходу блокировок здесь нет.
За нарушение законодательства о персональных данных и налоговой тайне отвечает организация и должностное лицо, а не нейросеть.
Типичные ошибки при первой сверке и как их избежать
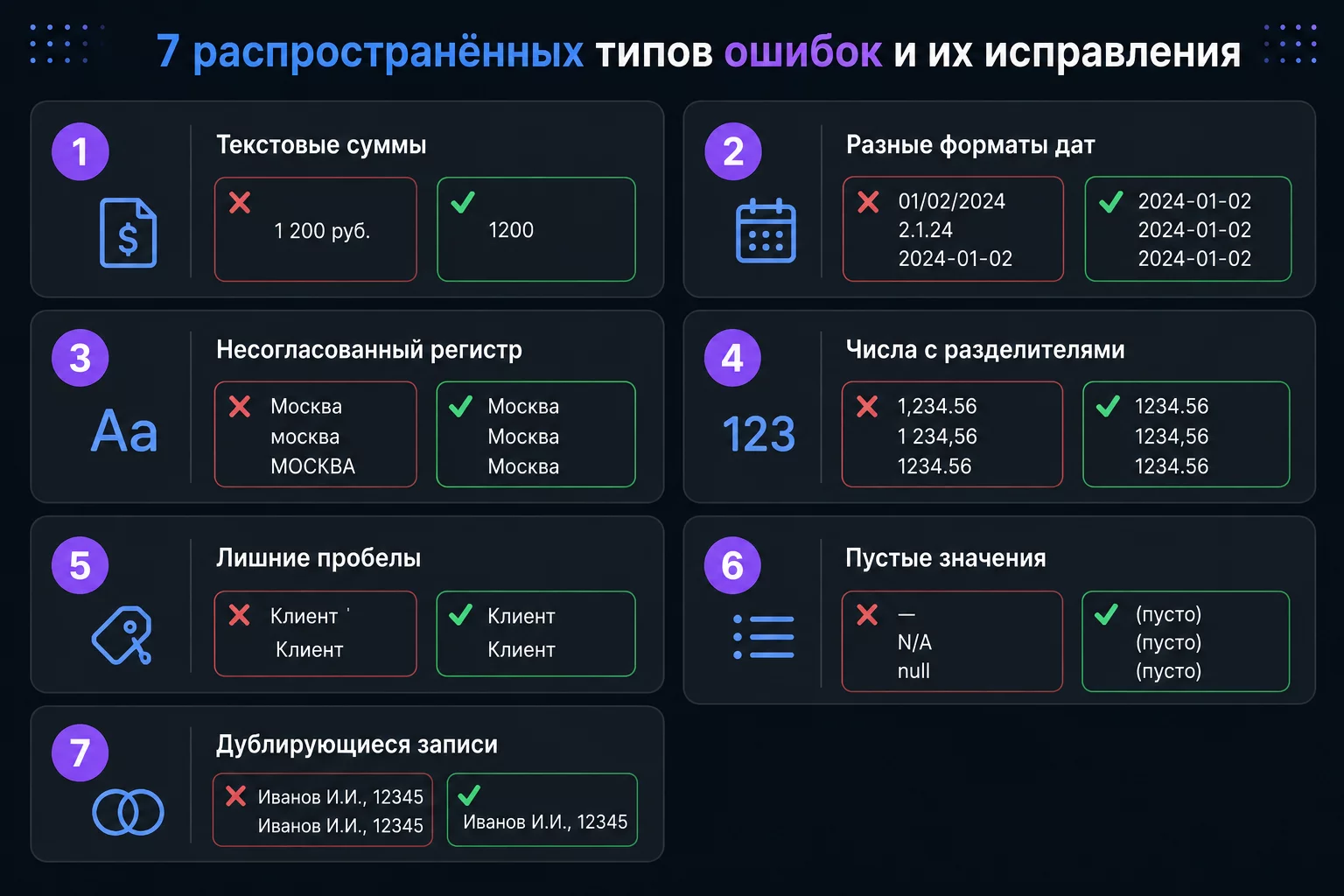
Ошибка 1. Текстовые суммы вместо числовых. Самая частая. После выгрузки из 1С числа выглядят как числа, но ChatGPT говорит «тип данных object». Причина: неразрывные пробелы как разделители тысяч. Исправление: Ctrl+H, найти пробел, заменить на пусто, задать числовой формат. Или в промпте: «Очисти разделители тысяч и преобразуй в числовой тип».
Ошибка 2. Разные форматы дат. Из 1С «31.05.2026», из банка «2026-05-31». При сравнении строк Python видит разные значения. Решение: указать форматы явно в промпте или привести к единому формату перед загрузкой.
Ошибка 3. Слишком широкий ключ сравнения. «Сверь по сумме» без контрагента приведёт к неверным парам при одинаковых суммах. Всегда добавляйте второй ключ: контрагент или номер документа.
Ошибка 4. Не проверить итоговые суммы. Красивая таблица расхождений получена, но сумма совпадений плюс сумма расхождений не равняется итогу исходных файлов. Контрольный вопрос после каждой сверки: «Посчитай итог по каждой из трёх групп и сравни с итогами исходных файлов».
Ошибка 5. Строки-итоги в выгрузке 1С. Excel-выгрузка из 1С часто содержит строки «Итого» жирным шрифтом. Code Interpreter читает их как данные, итоговая сумма задваивается. Удалите строки-итоги перед загрузкой или укажите в промпте: «Исключи строки где поле Контрагент пустое или равно “Итого”».
Ошибка 6. Не описать структуру файлов. «Сверь эти два файла» без объяснения структуры даёт плохой результат. ChatGPT угадывает, что где, и ошибается. Тратьте 2 минуты на описание каждого файла: колонки, что означает каждая, ключ для сравнения.
Ошибка 7. Данные на неправильном листе. 1С иногда сохраняет данные на втором листе Excel. ChatGPT читает первый по умолчанию и не находит данных. Укажите в промпте: «Данные находятся на листе “ОСВ”» или перед загрузкой скопируйте нужный лист как первый.
Какая нейросеть лучше для сверки: ChatGPT, Claude или Gemini
Code Interpreter это функция ChatGPT, но вопрос «а что с другими моделями?» возникает закономерно. Ответ зависит от задачи и способа работы.
Из четырёх инструментов полноценный Code Interpreter с запуском Python прямо в чате есть только у ChatGPT Plus с GPT-5.5. Именно это делает его главным выбором для сверки. Дополнительные плюсы: хорошая работа с кириллическими данными, понятные объяснения кода по-русски, возможность скачать результат прямо в чате.
Claude Sonnet 4.6 хорошо справляется с анализом текстовых данных и длинных документов. Инструмент выполнения кода у Claude есть, но прямой загрузки нескольких Excel-файлов с последующим скачиванием готовой таблицы расхождений в одном интерфейсе нет — в отличие от Code Interpreter, где весь цикл (загрузка, код, скачивание результата) происходит в одном чате. Для текстового анализа — акт взаиморасчётов на нескольких страницах, письмо от контрагента с позицией по спорным суммам — Claude хорош. Для вычислительных задач (слияние таблиц, поиск дублей по числовому ключу) ChatGPT с Code Interpreter удобнее.
Gemini 2.5 встроен в экосистему Google и работает с Google Sheets напрямую. Если ваши регистры хранятся в Google Таблицах, Gemini в режиме Workspace может работать с ними без выгрузки. Удобно для небольших объёмов. Для сложной двусторонней сверки из 1С и банка с нормализацией ChatGPT всё равно предпочтительнее.
DeepSeek V3.2 доступен в России без специальных средств доступа. Умеет писать Python-код, но встроенного выполнения кода нет. Работает как помощник по написанию скрипта: вы описываете задачу, он пишет код, вы запускаете его локально. Подходит для тех, кто хочет работать с данными без публичного облака.
Итог для финансиста: Code Interpreter в ChatGPT это лучший вариант для сверок из 1С и банка. Для текстового анализа актов и переписки с контрагентами Claude хорош в качестве дополнения.
Когда Code Interpreter не поможет: честные ограничения
Я не уговариваю финансистов бросить Excel и переехать в ChatGPT. Это инструмент под конкретные задачи, и у него есть ограничения.
Очень большие файлы. ChatGPT принимает до 512 МБ, но на файлах больше 100 000 строк замедляется и иногда анализирует выборку. Для тяжёлых регистров агрегируйте в 1С перед выгрузкой.
Бизнес-логика, которую нужно объяснить. Code Interpreter не знает что в вашей компании аванс закрывается через 45 дней, а не через стандартные 30. Эту логику описывайте в промпте явно.
Нет памяти между сеансами. Загруженные файлы и код не переносятся. Сохраняйте Python-код и промпт в личную библиотеку.
Не создаёт юридически значимых документов. Официальный акт сверки формируется через 1С или вручную и подписывается обеими сторонами. ChatGPT его не заменяет.
Нестандартные форматы 1С. Объединённые ячейки в шапке, числа в нескольких кодировках, многоуровневые итоги добавляют 10-15 минут на отладку. Это не блокер, но требует дополнительных итераций.
Как сохранить Python-код и запускать его повторно
Этот раздел экономит время начиная со второй сверки.
Когда ChatGPT выполнил сверку, в его ответе есть свёрнутый блок с кодом. Кликаете «показать код». Там реальный Python-код с pandas, который выполнил всю работу. Три варианта как его использовать.
Вариант 1. Запустить в следующем чате. Копируете код из ответа в Notion, OneNote или текстовый файл. При следующей сверке загружаете новые файлы и пишете: «Вот код предыдущей сверки. Обнови пути к файлам и выполни.» ChatGPT запускает его без переписывания промпта.
Вариант 2. Запустить локально. Если установлен Python с pandas (бесплатно, инструкции в открытом доступе), тот же код запускается на вашем компьютере без ChatGPT. Это важно для данных которые нельзя загружать в публичную нейросеть.
Используйте промпт 10 из нашей библиотеки: он просит ChatGPT добавить переменные FILE_1, FILE_2, PERIOD в начало кода. Следующий месяц: меняете только эти три строчки, остальное работает без изменений.
Вариант 3. Библиотека шаблонов. После трёх рабочих сверок потратьте 20 минут: создайте папку «Библиотека сверок» и сохраните по одному файлу на каждый тип сверки: промпт + Python-код + пример входного файла. Разовая инвестиция, окупающаяся при каждом повторном использовании.
От разовой сверки к автоматической: следующий шаг
Code Interpreter это хороший старт, но не финальная точка автоматизации. Расскажу что делают мои ученицы после освоения ручной сверки через ChatGPT.
Уровень 1. Ручная сверка через ChatGPT (старт). Загружаете файлы руками, пишете промпт, скачиваете результат. Экономия: 3-6 часов в месяц. Порог входа: 30 минут на первую сверку.
Уровень 2. Полуавтоматизация через n8n. n8n это конструктор автоматизаций без кода. Собираете сценарий: файл из почты или Google Drive > Python-скрипт (сохранённый код из ChatGPT) > результат в таблицу > уведомление в Telegram. Запускается по расписанию. Сверка происходит сама, вы только проверяете результат. Подробно про n8n для финансиста я разобрала в отдельной статье.
Уровень 3. API OpenAI с Assistants API. Для команд которым нужна полная автоматизация: Python-скрипт вызывает API напрямую, загружает файл, запускает ассистента с Code Interpreter, получает результат в структурированном виде. Запускается по кнопке или по расписанию.
Уровни 1-2 закрывают 95% задач финансиста. API-автоматизация (уровень 3) нужна тем, кто ведёт больше 20 организаций или хочет полностью убрать ручной шаг запуска. Главный совет: не перескакивайте на уровень 3, не освоив уровень 1. Автоматизировать сломанный процесс бессмысленно.
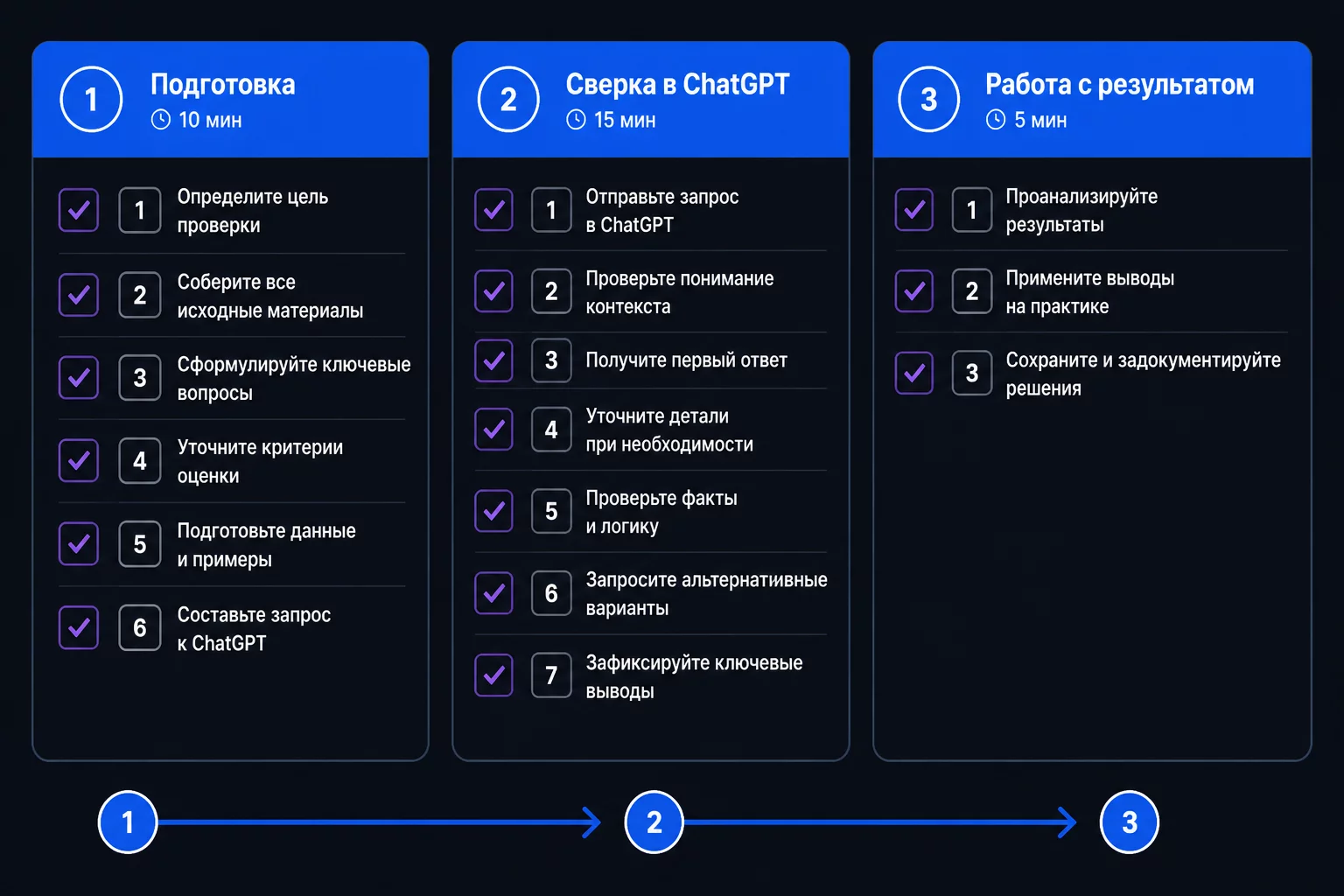
Чек-лист: сверка регистров через ChatGPT за 30 минут
Подготовка (10 минут)
- Выгружаю нужный регистр из 1С в Excel: ОСВ, карточка счёта или журнал документов.
- Выгружаю второй источник: банковская выписка, реестр поставщика, акт контрагента.
- Обезличиваю данные по справочнику: ИНН заменяю на К01, К02, названия на Контрагент 1, 2, 3.
- Проверяю форматы: суммы числовые, даты в одном формате, шапка в первой строке без пустых строк сверху.
- Удаляю строки «Итого» из выгрузки 1С.
- Сохраняю оба файла как .xlsx.
Сверка в ChatGPT (15 минут)
- Открываю chatgpt.com, тариф Plus, новый чат.
- Загружаю оба файла через кнопку прикрепления.
- Пишу промпт с описанием структуры каждого файла и ключа сравнения.
- Проверяю первые строки каждого файла в ответе ChatGPT.
- Запускаю сверку. При ошибке прошу «исправь и повтори».
- Прошу вывести итоговые суммы по трём группам и сравниваю с итогами исходных файлов.
- Прошу сохранить результат как Excel-файл для скачивания.
Работа с результатом (5 минут)
- Скачиваю файл, открываю, проверяю итоговые суммы.
- Копирую Python-код из ответа ChatGPT в библиотеку с именем типа «сверка_дебиторки_шаблон».
- Расхождения из топ-10 по сумме разбираю в том же чате, прошу предложить возможные причины.
Итого: 30 минут вместо 4-6 часов. Начиная со второй сверки, когда промпт и код уже есть: 15-20 минут.
Системно освоить нейросети и автоматизацию в работе финансиста: курс «AI-навыки финансиста» от онлайн-школы «Финансовый директор | Мастер CFO». 10 модулей, 800+ выпускников, диплом с лицензией, налоговый вычет 13%.
Наши каналы
Следите за новыми промптами, кейсами и разборами инструментов для финансистов:
- @findir_pro — основной Telegram-канал школы «Финансовый директор | Мастер CFO», 45 000 подписчиков. Ежедневные разборы AI-инструментов для финансистов и бухгалтеров.
- @ai_finansist — второй канал школы «АИ с Софьей и Натали», 13 000 подписчиков. Еженедельные разборы новых моделей и практических кейсов для финансистов.
- MAX — закрытое сообщество 5 000+ выпускников и учеников школы. Здесь делятся промптами, кейсами и задают вопросы в реальном времени.
Об авторе
Натали Васильева — эксперт по нейросетям и продюсер онлайн-школы «Финансовый директор | Мастер CFO» (основатель школы — Софья Бурцева). С нейросетями в финансовых задачах с февраля 2023 года, 800+ выпускников курса AI-навыков. Веду Telegram-канал @findir_pro, 45 000 подписчиков.